In the early morning hours of October 20, Amazon Web Services suffered from what became a multihour outage that affected a multitude of websites, apps and platforms. Throughout the day several fixes were deployed though outages continued to affect a wideswath of services from banking apps to college instructional platforms and more.
Collectively, reports on Downdetector hit a high of over 50,000 reports starting around 7:50 am.
For the unaware, AWS is crucial backbone of the internet acting as infrastructre for apps and websites the likes of Snapchat, Venmo, Ring, Pokémon GO and more all went down down because of AWS' outage.
Specifically, a hub dubbed US-EAST-1 Region went down affecting people on the east coast and any services that are based on infrastructure out of the region.
We followed the outage collecting information from various services, purusing details on when a fix could be put in place and seeking comment from Amazon.
Despite a number of fixes reported by AWS, the deployment was slow and the repairs took time.
In all the bulk of the outage lasted more than 12 hours starting a 1 am Pacific and running all the way through 3 pm Pacific. And it wasn't exactly over by then, but services appeared to be coming back online in a more functional state.
As part of our coverage, we looked at all the apps and services affected by the outage (and are certain we didn't catch them all) as well as how the outage happened and why it broke the internet. Helpful readers pointed out broken services like Canvas for college students and small business applications like Shopify and ShipStation that were affecting businesses and education.
Separately, we monitored Snapchat and Venmo as both services seem totally out of commission and received the most reports.
Here's the timeline
- At around 12:11am PDT (3:11am ET, 8:11am BST), AWS started experiencing outages. And as AWS is the backbone of most of the internet, it took out hundreds of websites and services with it.
- We started seeing huge spikes in outage reports for apps like Snapchat, Venmo and Ring, Amazon services like Alexa, and games like Fornite and Pokémon GO.
- At 1:26am PDT (4:26am ET, 9:26am BST), the issue was diagnosed as a big one related to the DynamoDB endpoint of AWS — the digital phonebook of the internet.
- At 2:01am PDT (5:01am ET, 10:01am BST), the specific problem was identified and work on a fix began.
- At 2:22am PDT (5:22am ET, 10:22am BST), the fix was deployed and since then, service has been slowly but surely returning to normal.
- BUT THEN, Reddit went down, and AWS updated saying there is a backlog of issues to work through.
- At 4:48am PDT (7:48am ET, 12:48pm BST), Amazon has found a fix but is still working on issues, as Ring and Chime are experiencing outages.
- At 5:48am PDT (8:48 ET, 1:48pm BST), more fixes are being applied. But almost in an interesting game of whack-a-mole, Wordle is down, and Snapchat users are experiencing outages too. The AWS outage reports are slowly starting to creep up again.
- At 9:15am PDT (11:15 am ET, 4:15pm BST) we started seeing a huge spike in reports for Venmo, a popular payment app. This came shortly after AWS said it was still investigating the root cause and identifying mitigations. It's still an issue and most definitely not resolved yet.
- At 10:03am PDT 1:03 pm ET, 6:15pm BST) AWS posted some updates, but it didn't add much other than letting us know it's working on the problem. At 10:38 PDT, the compay said, "We are applying mitigations to the remaining AZs at which point we expect launch errors and network connectivity issues to subside."
- At 12:15 p.m. PDT (3:15 ET, 8;15 BST) AWS posted some updates that the claimed services were starting to return with some intermittent function errors. We've also seen a slow but steady decrease in reports on Down Detector.
- Between 1:00 pm PDT and 2:30 pm, AWS posted cautious updates about slowly reducing throttles as the company brought more features back online.
- At 3:00 pm PDT (6 ET, 11 BST) AWS closed the issue listing as resolved and blaming it on a DNS issue and nin internal subsystem that didn't resolve after a DNS fix.
That's a big spike!
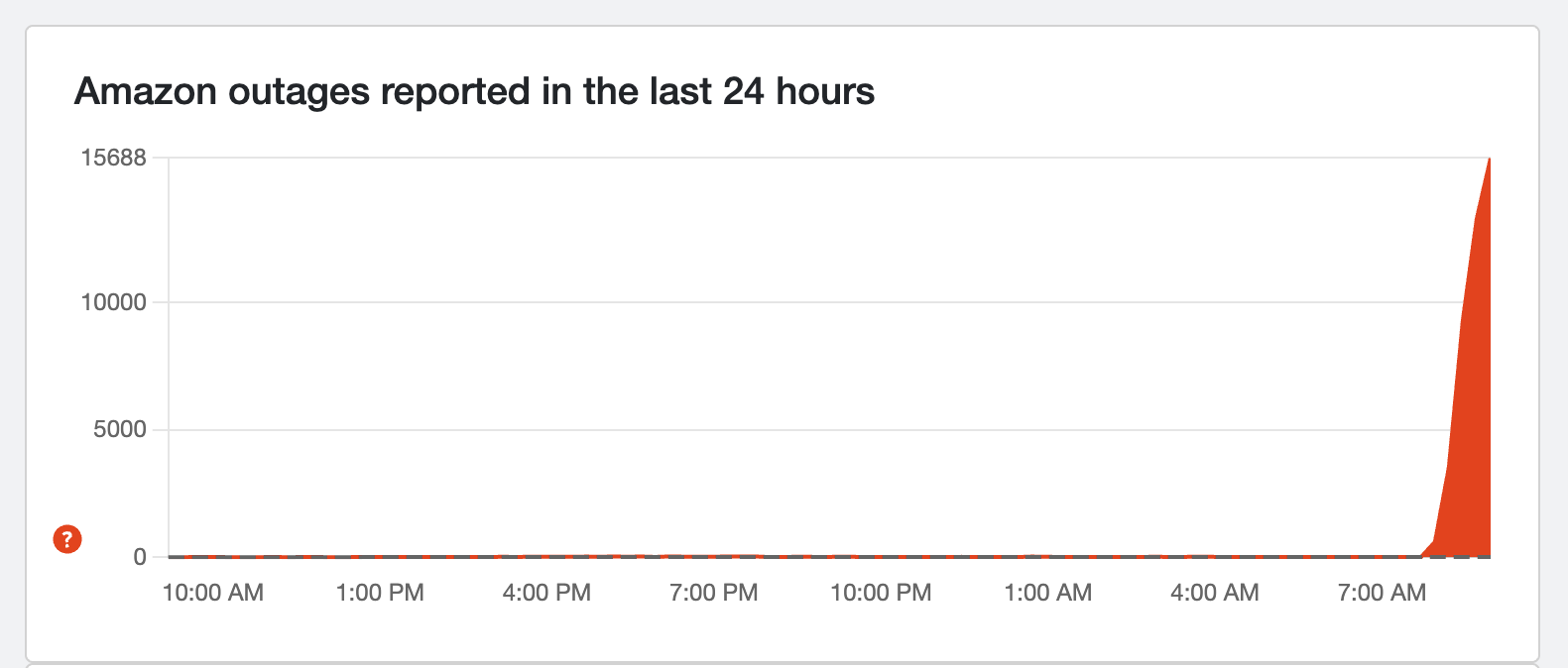
For Amazon alone (excluding Alexa and AWS), reports have hit over 15,000 with no signs of slowing. Most users are reporting that the mobile app is hit heaviest.
The big one here is AWS
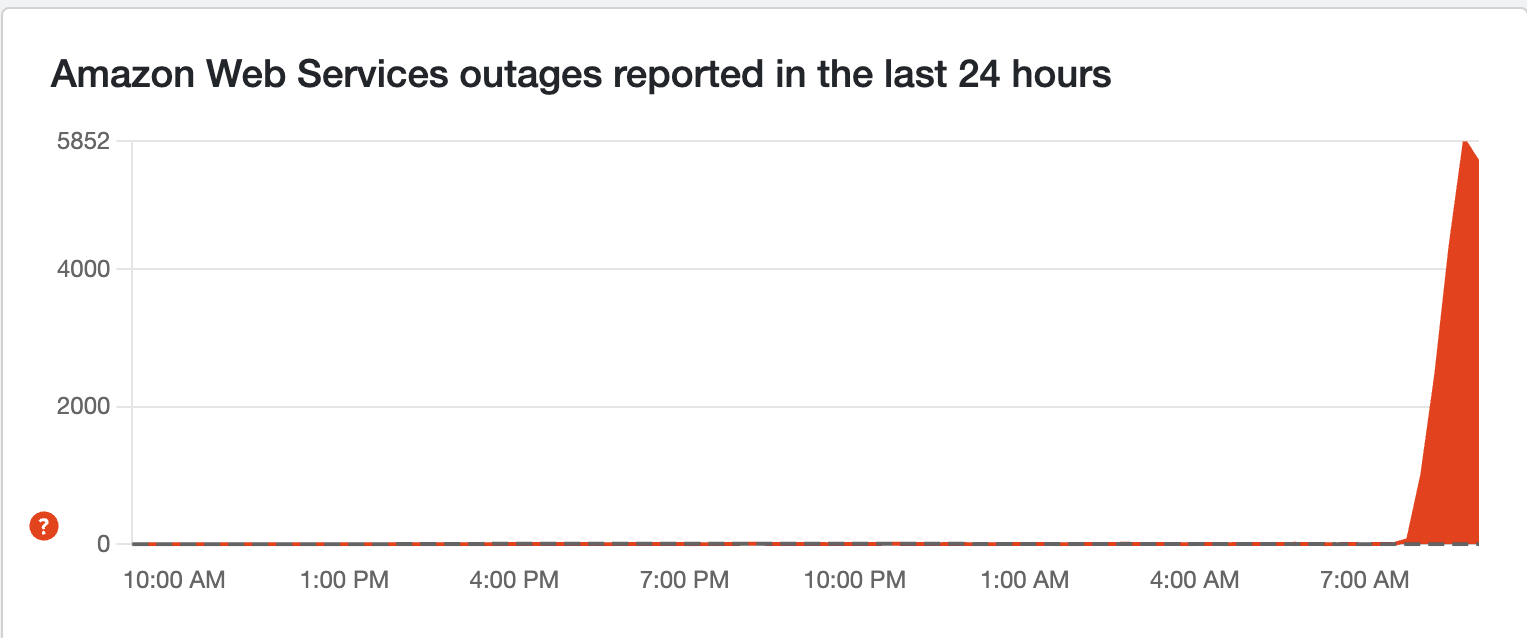
Amazon Web Services (AWS) is responsible for hosting a whole lot of services and websites across the web. And because of servers going down across the planet, it's having a knock-on effect on other websites, services and games.
For example, huge outages are being reported at Snapchat, Robinhood, Venmo, Roblox, Fortnite, Ring, Epic Games Store, Lyft, Pokémon GO and many more.
Here's what's going on
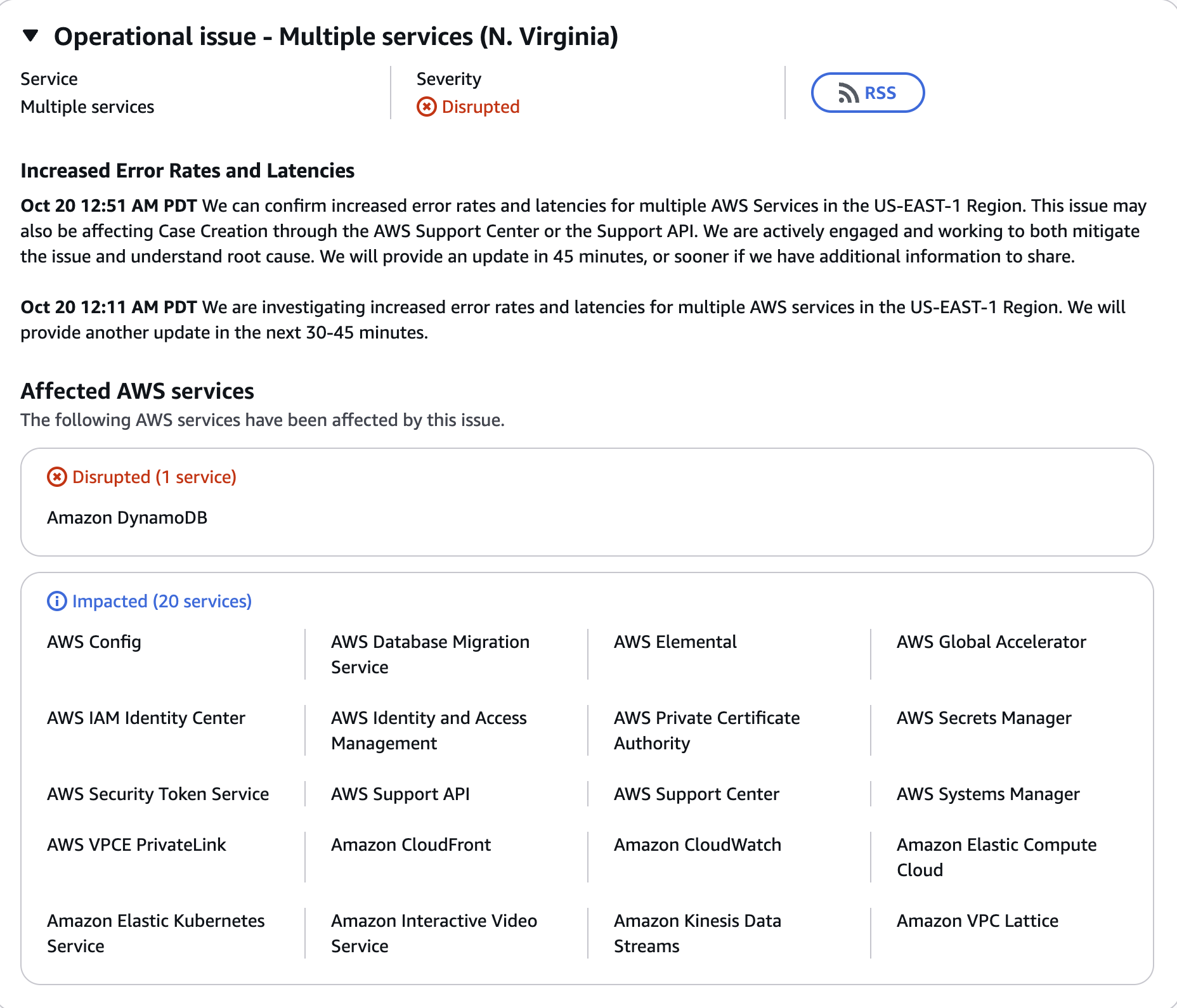
So...there's a real technical issue going on here. It's disrupting DynamoDB and impacting 20 other services, which leads to "increased error rates and latencies."
Let's break it down — imagine AWS as the huge digital power plant for the internet. North Virginia (US-EAST-1 Region) is one of the biggest neighborhoods this plant serves. The increased error rates means a lot of packages of data are getting dropped or sent to the wrong place, and the latencies mean that those delivery trucks are moving really slowly.
More on the AWS issue
What is Amazon DynamoDB? Think of a super-fast digital filing cabinet that many apps use to save and find info quickly (like user profiles or game scores). With this being disrupted, things that rely on it will likely stop working (as we're seeing across a whole lot of services).
As for the 20 other services that are impacted (affected but not totally broken), these will cause the services to run slowly or have hiccups. This was first reported at 12:11am PDT (3:11am ET, 8:11am BST).
The problem is global

Meanwhile, a look over at Down Detector in the UK shows how widespread this is. The AWS outage in North Virginia is hitting us Brits too, and it's impacting Snapchat, Ring, all the usual suspects. Concerningly, it's also hitting banks too.
What streaming services have been hit?

If you were looking to stream your favorite movies or TV shows, you may be running into some issues! Disney+, Prime Video and Hulu have been hit by this outage.
A fix may have just been implemented
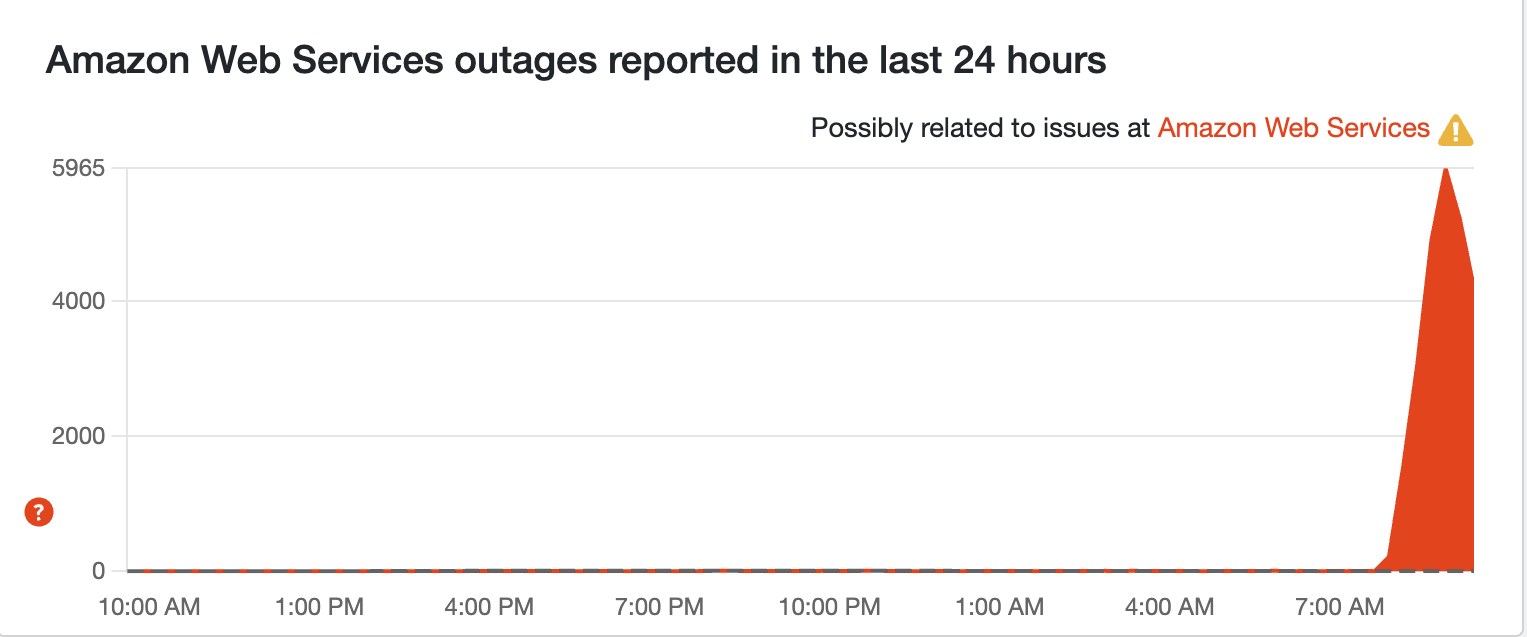
Standby for more, but we're seeing the peaks of outage reports start to fall off. All we know at the moment is that Amazon is working on the issue. The devs may have identified the problem.
Update from Amazon

"Engineers were immediately engaged and are actively working on both mitigating the issues, and fully understanding the root cause," a rep from AWS has said in the most recent update on the progress fixing this outage.
Something's happened

You can see how the symmetry of these peaks match up quite nicely with AWS' movement. My suspicion is the team has identified the issue. But we'll wait and see...
No sign of this in the UK

This is what's making me a little cautious to say the issue has actually been fixed. In the U.K. those outage graphs continue to go up.
The most concerning part about the U.K. side of things
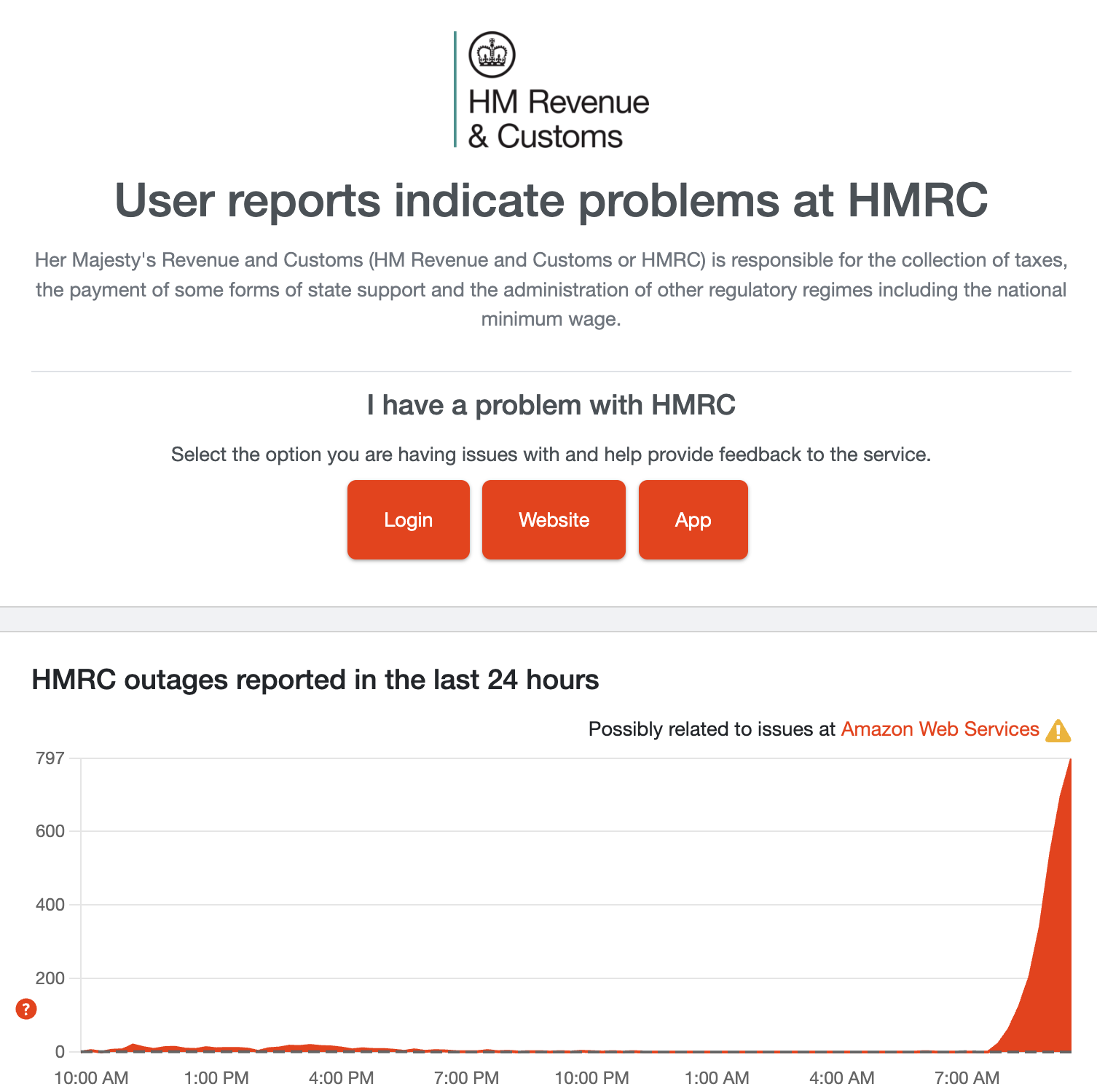
While in the U.S. it's looking like all private companies have been hit by the AWS issues, in the U.K., the issue is a little more deeply rooted in some key infrastructure.
Online banking is down, and most concerningly, it's looking like it's impacting government services too.
Coinbase is down, but your funds are safe
We're aware many users are currently unable to access Coinbase due to an AWS outage.Our team is working on the issue and we'll provide updates here. All funds are safe.October 20, 2025
Just to reassure anyone who trades crypto and has seen themselves unable to jump in to see their walled, Coinbase has confirmed that "all funds are safe."
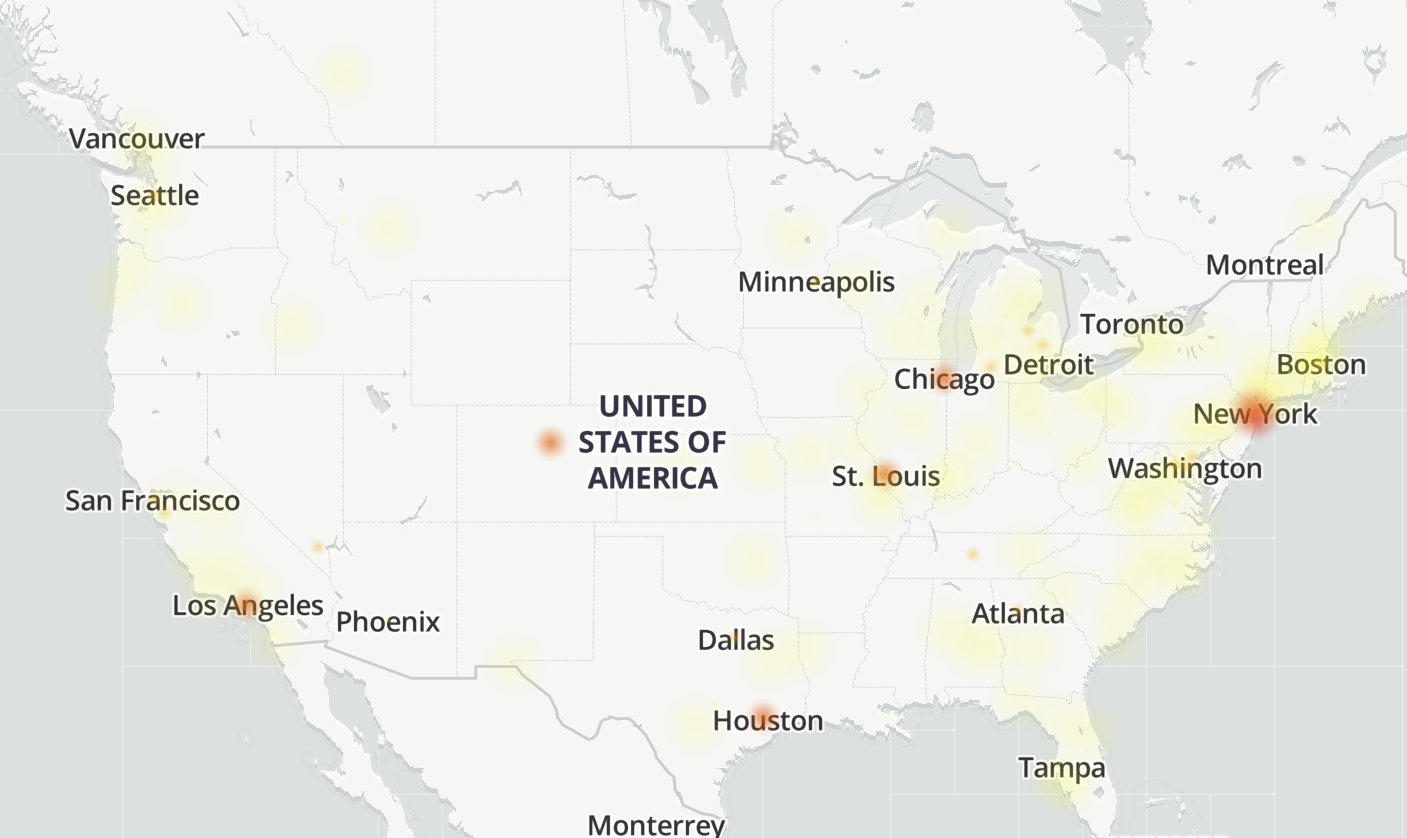
Don't believe the Ring status page
@ring sort your systems out, I can’t connect to your app, I can’t login online. my cameras are all down, I can’t see no history, I’m not getting any detection notifications. What kind of security service is this. Your service should be impossible to go down. pic.twitter.com/FjmxLtivWQOctober 20, 2025
This is a weird one. We all see the spike on Ring doorbells service on downdetector. Yet, the status page shows it's appearing as operational.
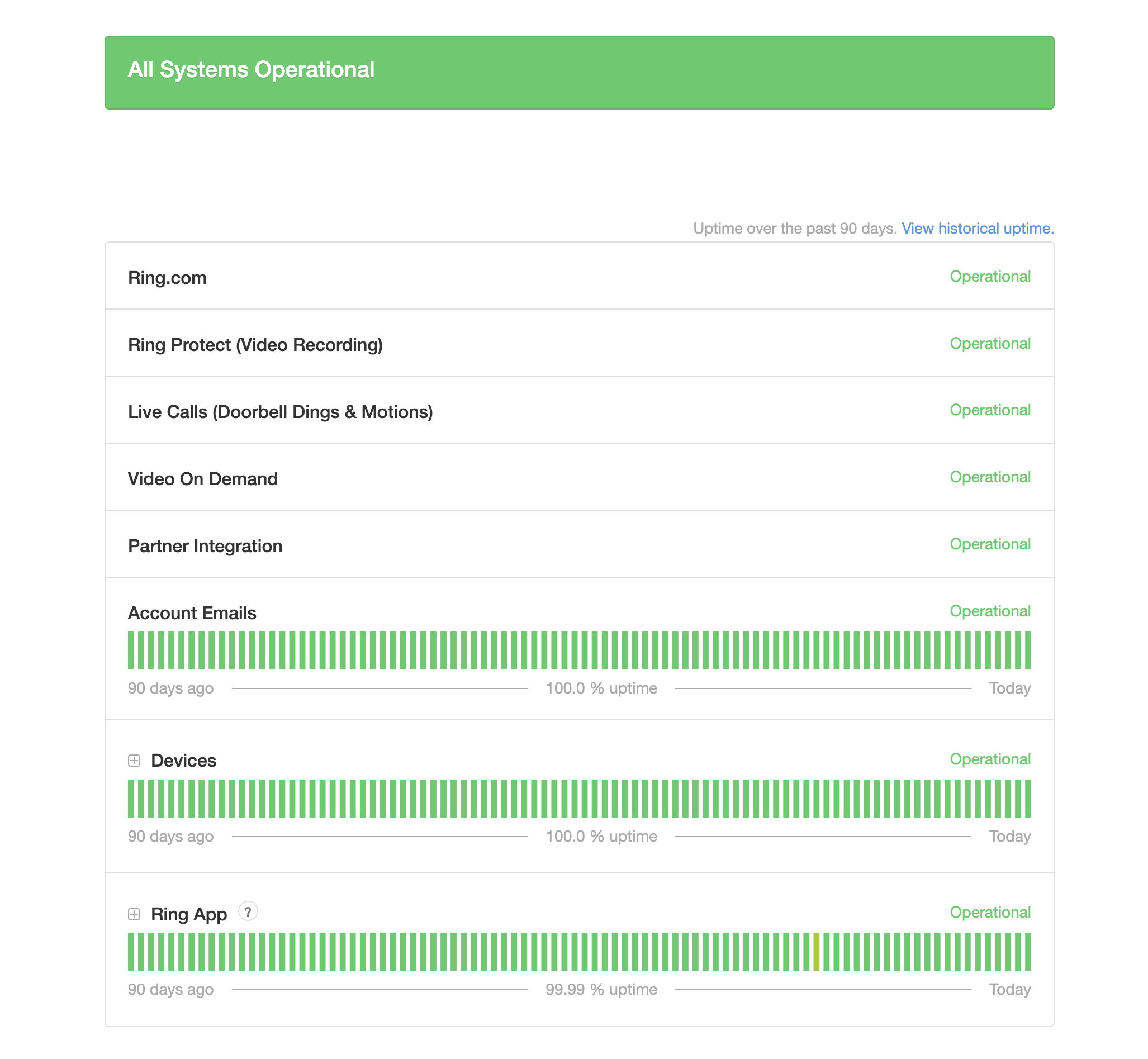
Surely this page would update in real-time with issues spotted, so no idea why it hasn't when AWS goes down. "No incidents reported today" reads the Oct 20, 2025 status.
OpenAI impacted
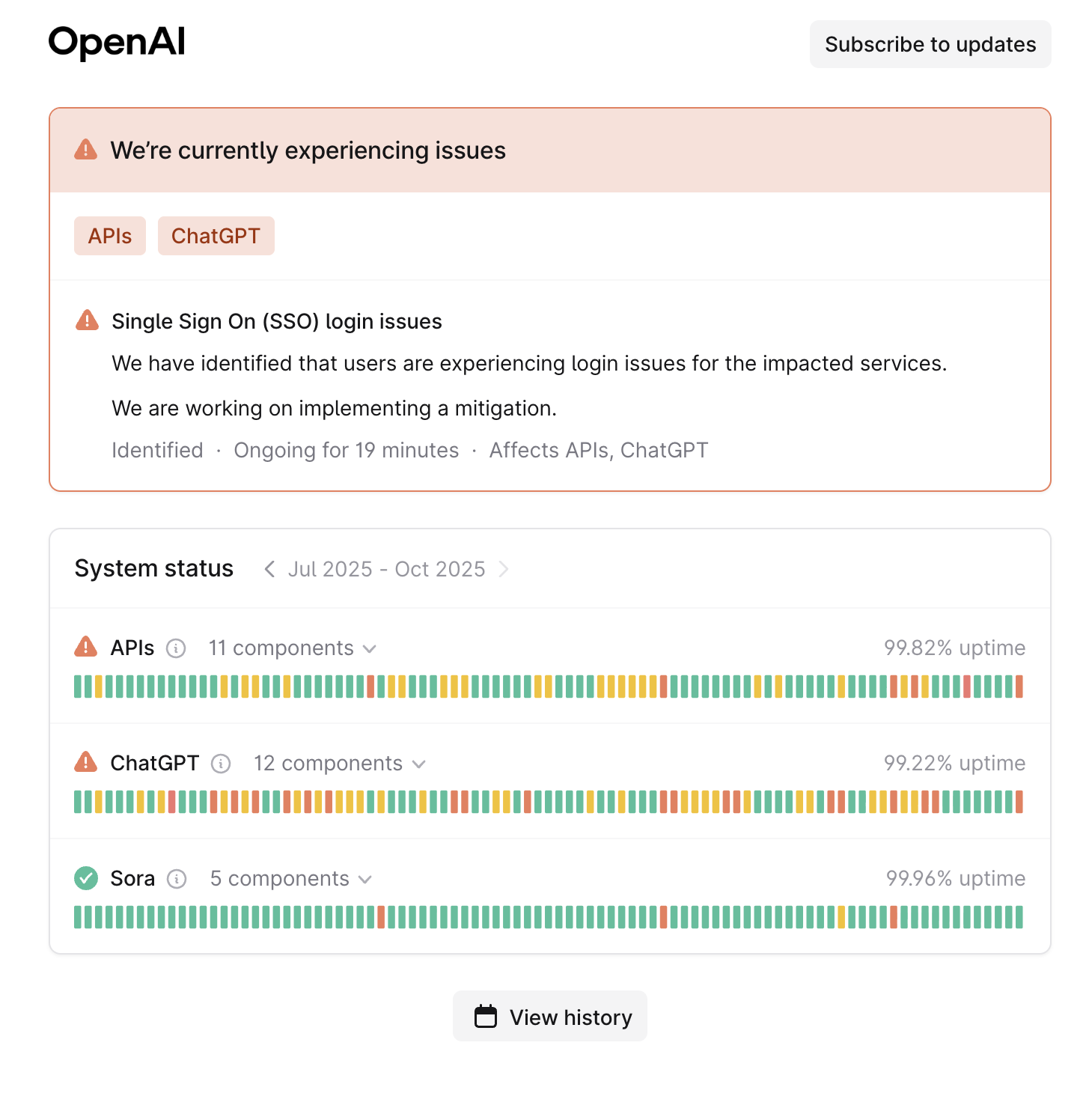
Looks as if some of OpenAI's services rely on AWS too. They're experiencing some Single Sign On (SSO) issues that will stop people logging into their ChatGPT, and the API for developer's apps to work.
The 2am update has not happened
According to AWS, an update will be shared "as we have more information to share, or by 2:00 AM."
This hasn't happened, so I'll update you instead! It looks as if some of the AWS issues with the US-East-1 region (what looks to be one of the key centerpoints for a lot of the internet) have been resolved, but not all the way. Reports have started dropping by 20-30% across the board.
These updates haven't hit the UK yet, as reports continue to be high with no sign of tailing off.
Lonely hearts
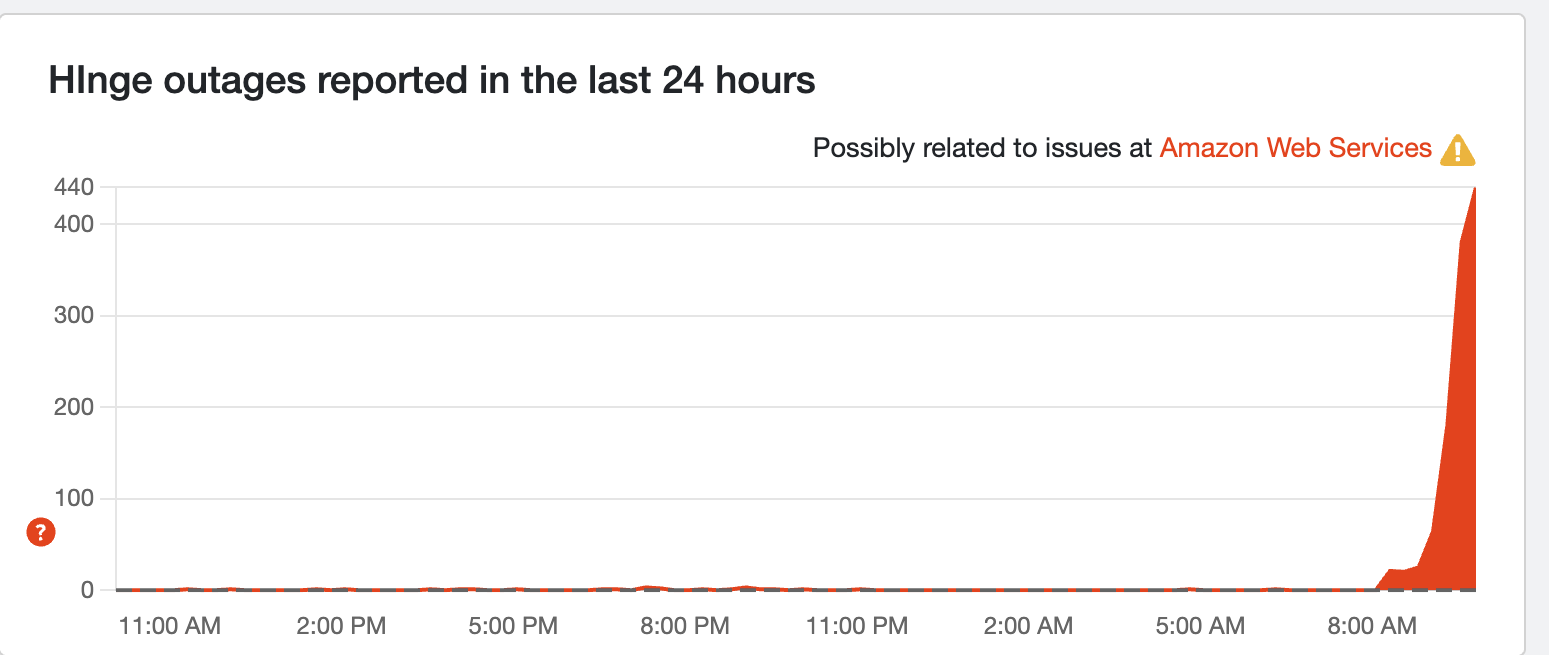
Dating apps are also being hit too, as Hinge has been disrupted by the AWS outage. People are experiencing app opening faults and server connection issues.
BREAKING: Update from Amazon

We have an update! Let's break it down. In short, Amazon's found the main bad guy, and it's a DNS issue!
DNS is the internet's phone book, packing a name (the URL) and a secret phone number (the IP address).
All of these are stored in the digital filing cabinet known as DynamoDB, and several fixes at once are being deployed to speedily fix this issue.
Amazon recommends that if anyone is facing issues to "continue to retry any failed requests."
Heading in the right direction

With AWS working in parallel on multiple fixes, it looks as if they're starting to take affect. in the U.S., outage reports are on the way down, and in the U.K., it's peaked with a few key services reports starting to come down too (think banks and government services).
People are worried about Venmo
Me seeing that @Venmo is down knowing it’s holding all the money I have to my name pic.twitter.com/8eEZgBpexuOctober 16, 2025
And understandably so! Venmo is holding a lot of customer money right now, and with outages to the app, people can't get to it!
Problems with airlines too!
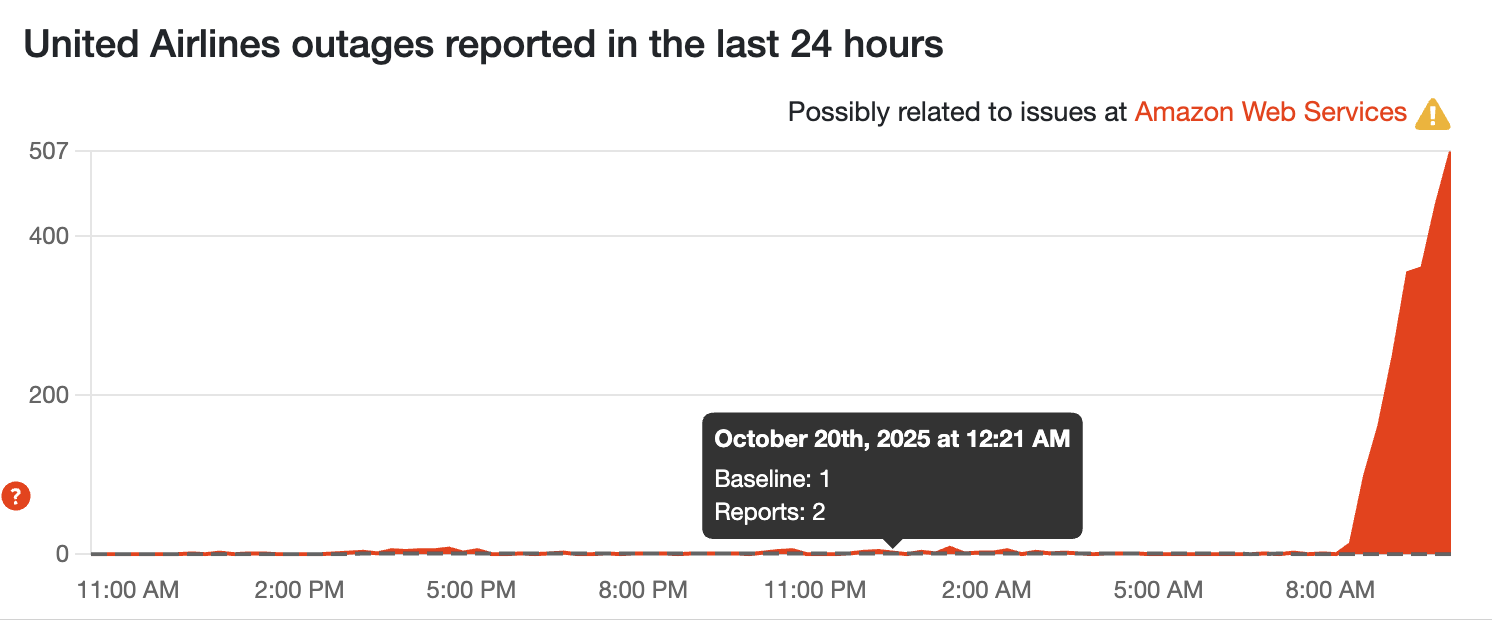
United airlines is down, and users of other airlines are experiencing app problems too.
Roleplayers are facing problems too!
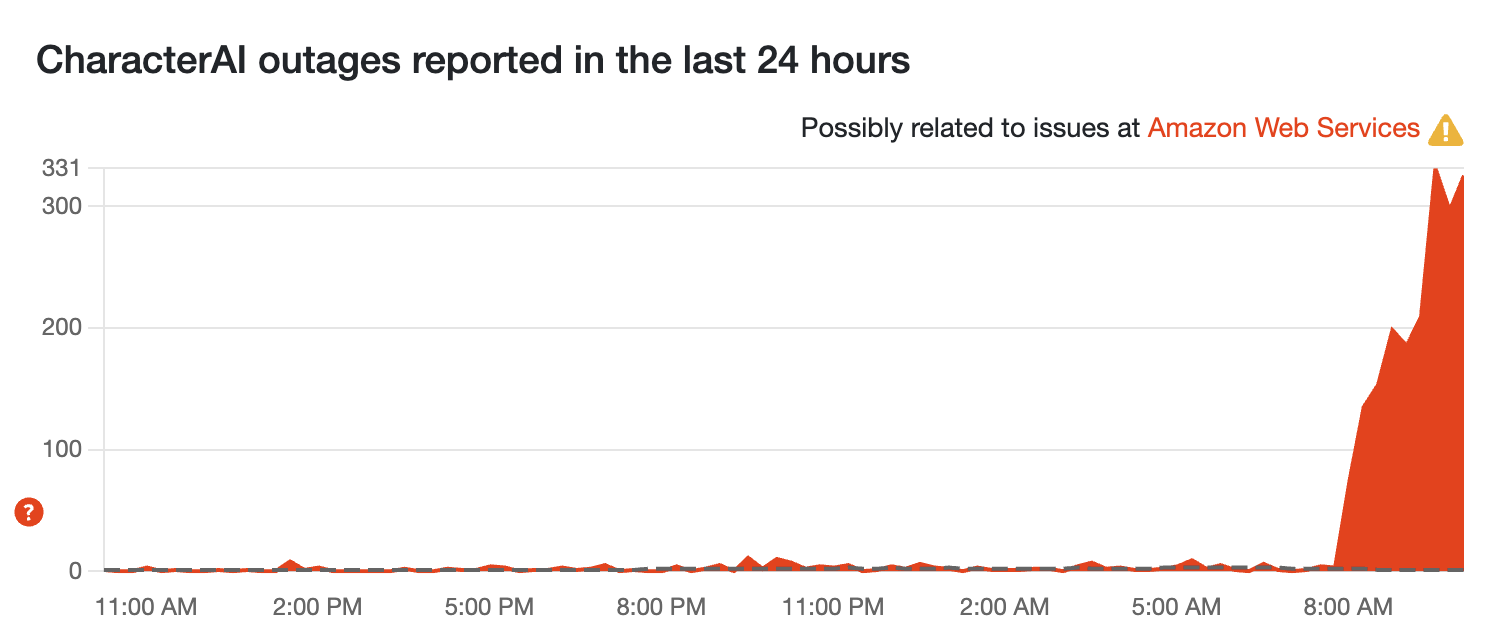
CharacterAI is serving as a resource for all your RP needs with an AI avatar. But since it's a service running on AWS, we're seeing outages here too!
Elon Musk gets smug about it
𝕏 worksOctober 20, 2025
Because of course he does. Also, for context, X went down on March, May and July this year (so far).
BREAKING: update from Amazon

OK! Now we're getting somewhere. According to the most recent AWS update, the fix is starting to work. The first big fix is in place, fixing the DNS problem (correcting the digital phonebook), and that is creating some "early signs of recovery."
But Amazon is not done yet. Things will be bumpy for a while as additional latency is expected (traffic will be moving slowly for a while), and there's still a big backlog.
But in short, Amazon's hit the "go" button on the fix, and they're watching to make sure it works.
Uh oh... Reddit just went out
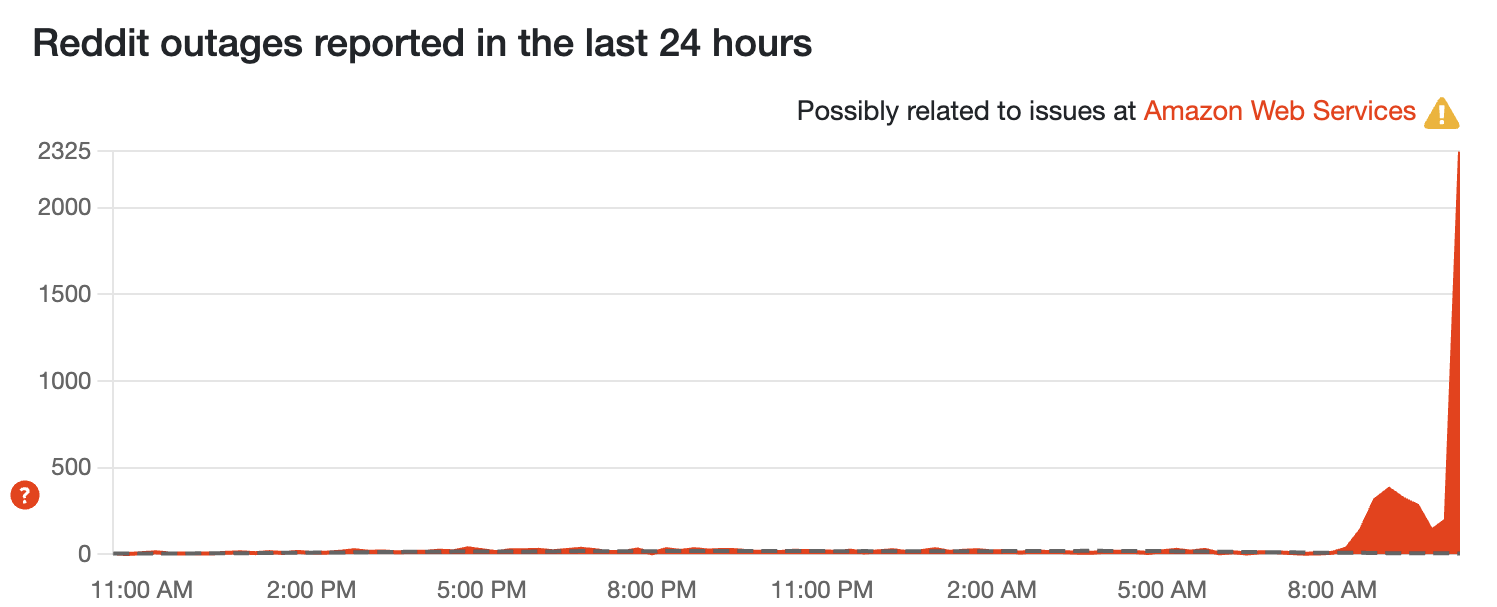
That's a huge spike of Reddit outages! Just happened.
Desktop Reddit still works — but mobile app is down

Well this is awkward. As other services seem to be seeing services gradually get back to normal, AWS' fix may have knocked out Reddit's app.
Over 2,000 reports were made in the past 5 minutes on down detector. Luckily, it seems to just be the app, as the website is working in all our tests.
BREAKING: Another update from Amazon

So it looks like Amazon pressing the "Go" button appears to have fixed it. The team is working through a "backlog of queued requests," but things are on the up and up.
Someone tell that to Reddit, though!
The data backs it up
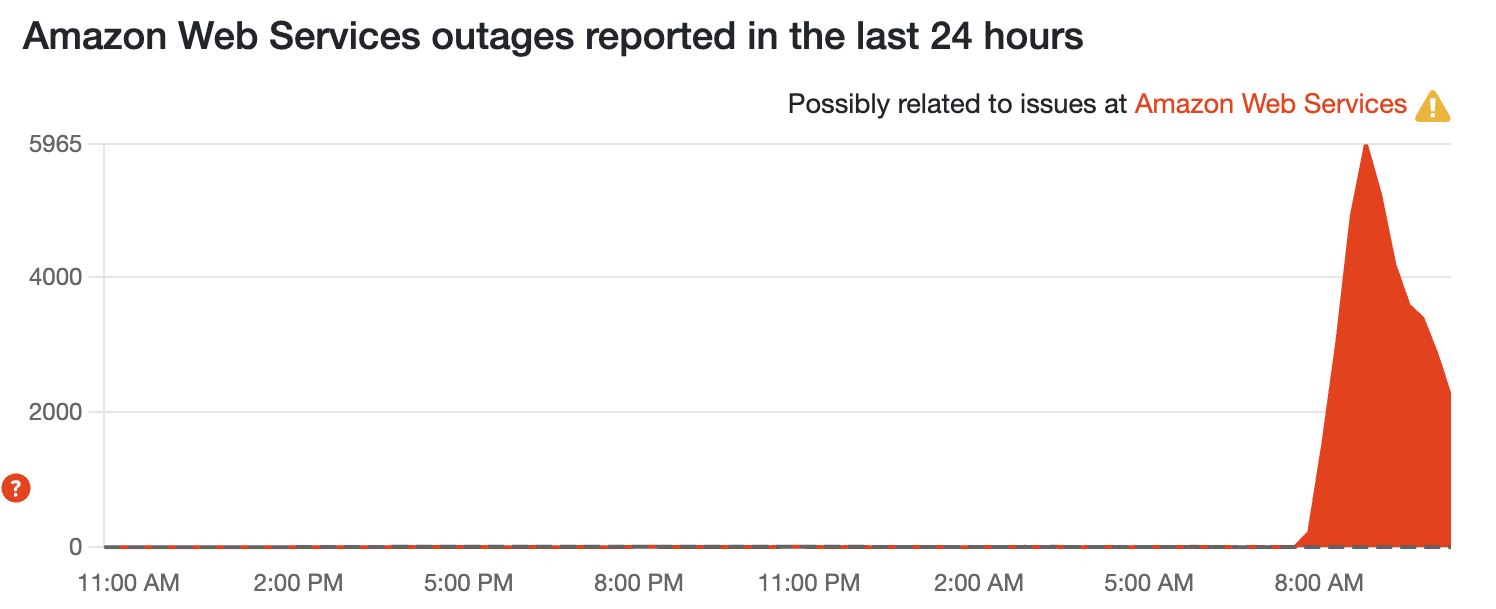
Amazon has claimed that there are "significant signs of recovery," and the outage reports are dropping off quick on the AWS down detector. Fingers crossed this isn't just a "fixing your own front door at the expense of others" kind of situation (the dropping reports across other services indicate this isn't the case), but we'll keep an eye on it.
What Redditors are seeing
reddit is down pic.twitter.com/50wb8UCe8bOctober 20, 2025
This is what a lot of people on Reddit are seeing. This is indicative of the DNS and latency issues experienced in this AWS outage. Basically, the digital phonebook has been corrected, to take people to the right place, but the lanes of traffic haven't been fixed properly yet.
This is creating huge tailbacks on the digital highway of the internet, and causing loading issues like this. As per Amazon's advice, keep trying as things gradually go back to normal!
U.K. kinda sorta getting back to normal

Things seem to be on the way back to normal in my homeland. Government services are back to normal, and banks are on the way back.
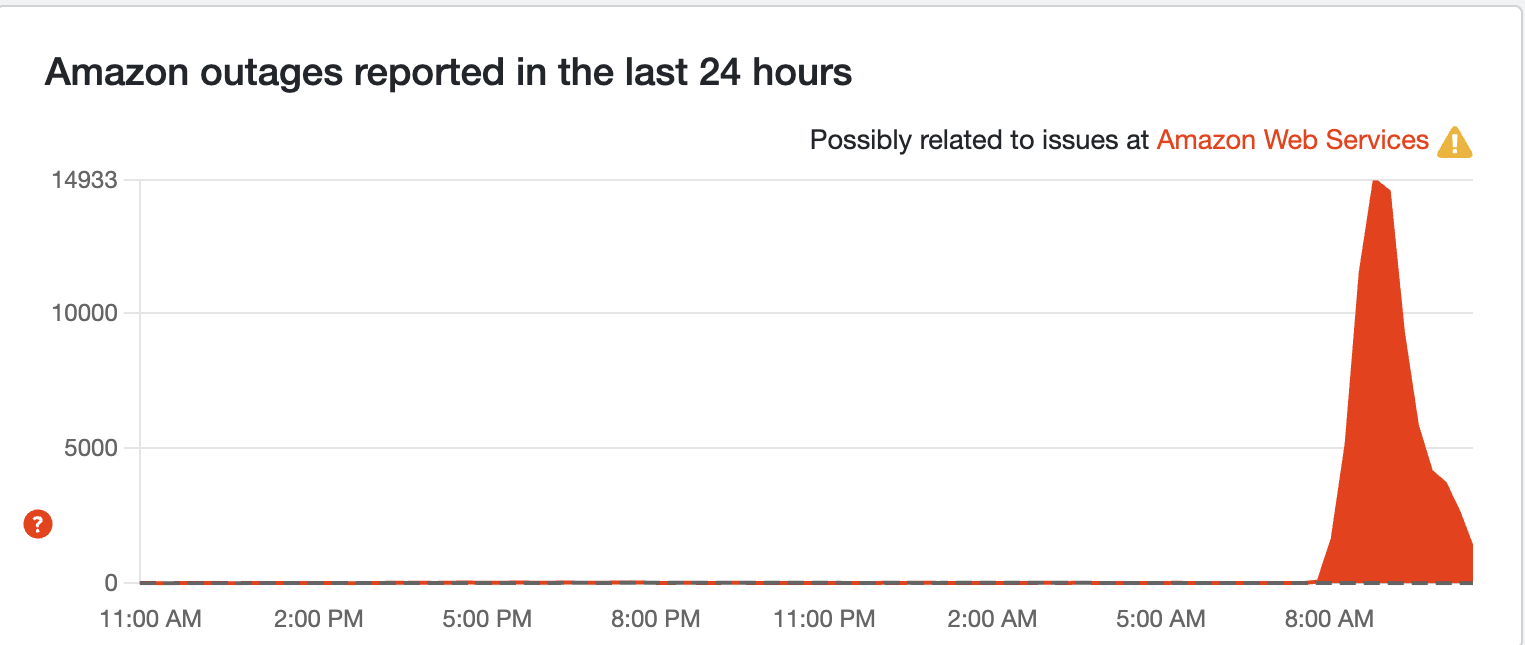
Amazon outage reports are down below 1,000. Chances are most of you can start shopping again on the app!
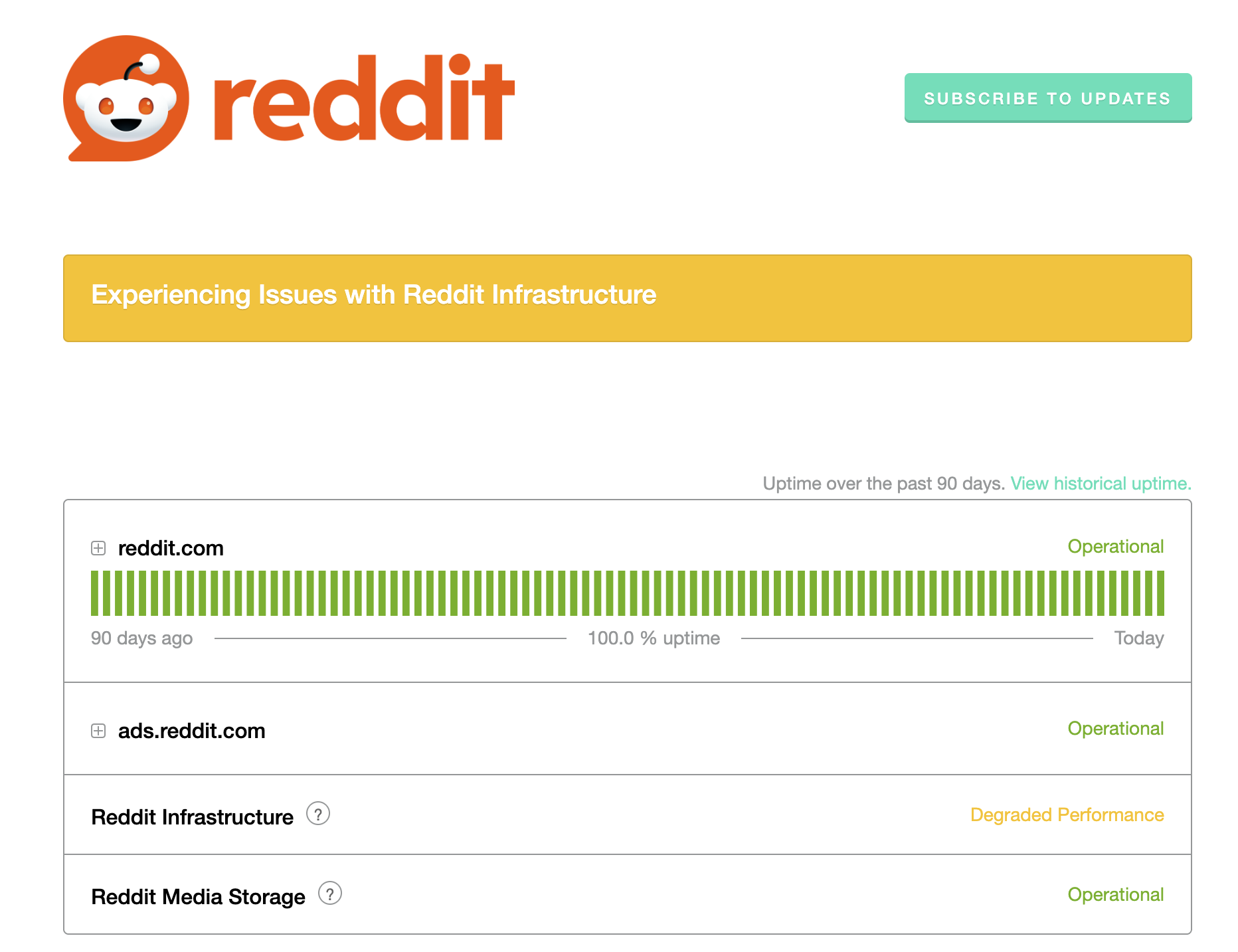
So far, according to the Reddit status page, the infrastructure of the service is undergoing "degraded performance," which is backed up by nearly 5,000 outage reports on Down Detector!
Gamers rejoice! Things seem to be (almost) back to normal

Roblox is back to normal levels, Epic Games Store service seems to be back online (and Fortnite by extension), Dead by Daylight has resumed, and Steam, Rocket League and Pokémon GO are almost back to normal.
PlayStation Network is showing no issues too. Looks as if the fix has resolved some of the anti-cheat issues that seem to have caused the blockages due to AWS.
Wordle is back!

One of the more painful ones to us (given we love playing it every day and finding/sharing the answer) is Wordle. Wordle runs on AWS, and the network outage caused this to go down too. Now, fortunately, we're back up and running. Happy wordling!
Square is now back
A lot of the internet's payment systems runs on Square, and it was knocked out by AWS outages. Now it's status has changed to up, so that should be resolved.
BREAKING: Next update from Amazon is good news

Amazon is continuing to see "recovery across most of the affected AWS services." On top of that, the company confirms that "global services and features that rely on US-EAST-1" have also recovered.
With this in mind, we should start to expect a lot of these impacted services across gaming, streaming, banking and more to return to normal.
Reddit spikes in U.K. too
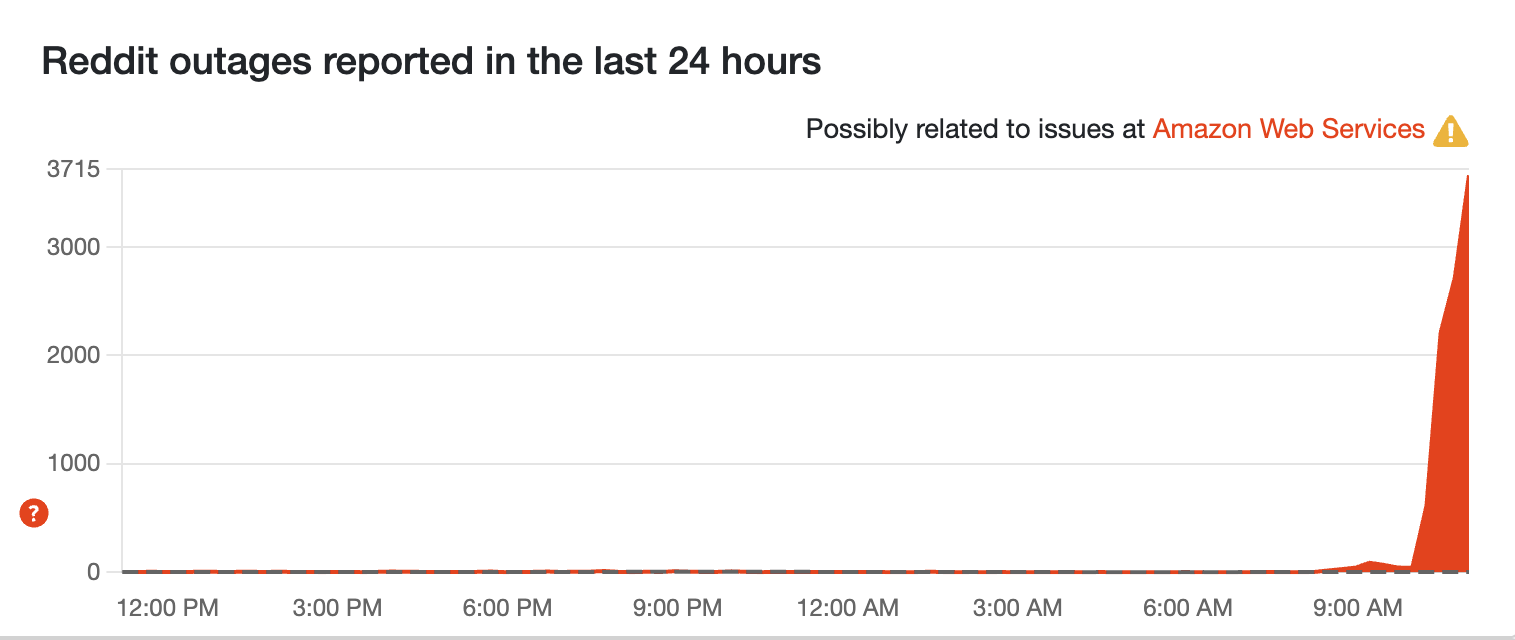
This seems to be both app and website loading. How is Reddit going in the wrong direction when the fix is deployed!? We're looking into this now
Over 9,000 outage reports for Reddit now!
55% of people reporting the app is down, while 34% are complaining about website outages. It's a sticky situation that seems to stretch beyond AWS fixes. Or there could be a scenario where the deployment of AWS' fix has knocked out Reddit. Nobody can be sure as Reddit's status page only reports "degraded performance."
Revenue loss expected in retailer chargebacks

With AWS outages, retailers get hit hard. It's one thing to talk about the outages of free services users are on. But what about retailers and paid-for services. They can cause issues like duplicate charges, broken confirmation pages and more.
“When AWS sneezes, half the internet catches the flu. Outages like this cause frustrated users, but also triggers a domino effect across payment flows," Monica Eaton, Founder and CEO of Chargebacks911 and Fi911 commented. "Failed authorizations, duplicate charges, broken confirmation pages, all of that fuels a wave of disputes that merchants will be cleaning up for weeks. And once a customer files a dispute, you are already on the back foot.”
Her advice to retailers seeing this? Get ahead of it: “The outage will end long before the disputes do. Any business that treats this as a one-day incident is already behind. Downtime happens, but silence and slow responses are what cause real damage.”
Ring is still down
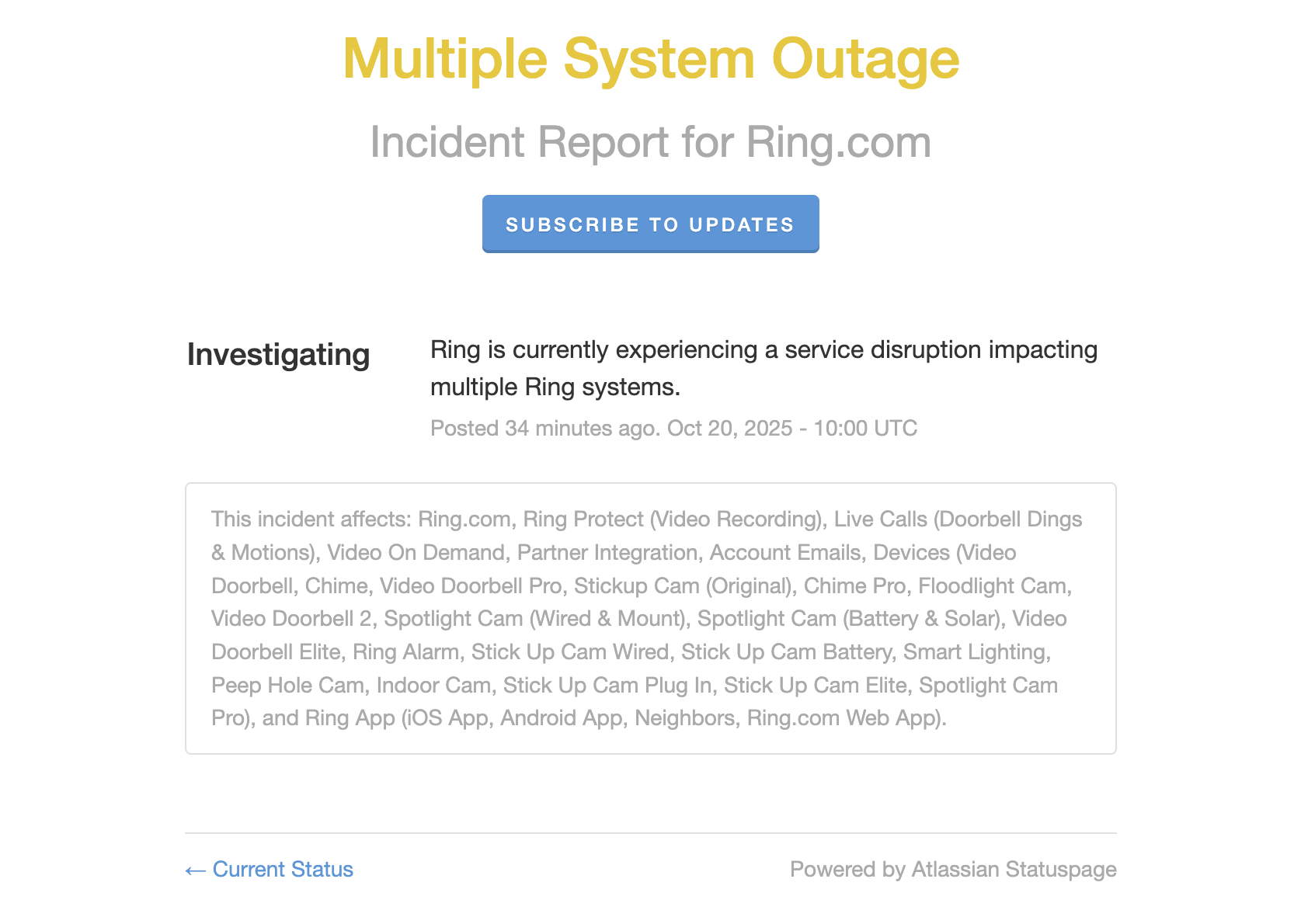
Even though the AWS fix is deployed, Ring is still down for many people. Ring has (finally) acknowledged the outage across all its services and apps, and the Down detector outage reports are going back up.
BREAKING: Amazon confirms crisis is over, but a few issues to clean up

OK, so we have a new update from Amazon! In short, things are just about back to normal. The underlying DNS issue has "been fully mitigated," so the internet phonebook problem has been resolved. And because of that, "most AWS service operations are succeeding normally now."
But we're not fully out of the woods yet, as there are some lingering issues here. Namely "a backlog of events," as the giant traffic jam is still clearing for some specific tools like Lambda that runs code, and Cloudtrail that keeps a record of all the activity. I'm certain that Reddit uses these two services, so it's no big surprise to connect the dots and see this still being knocked out of service.
BREAKING: Reddit is on the case
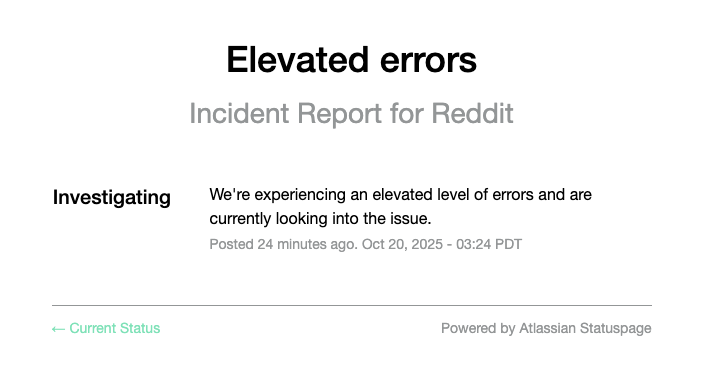
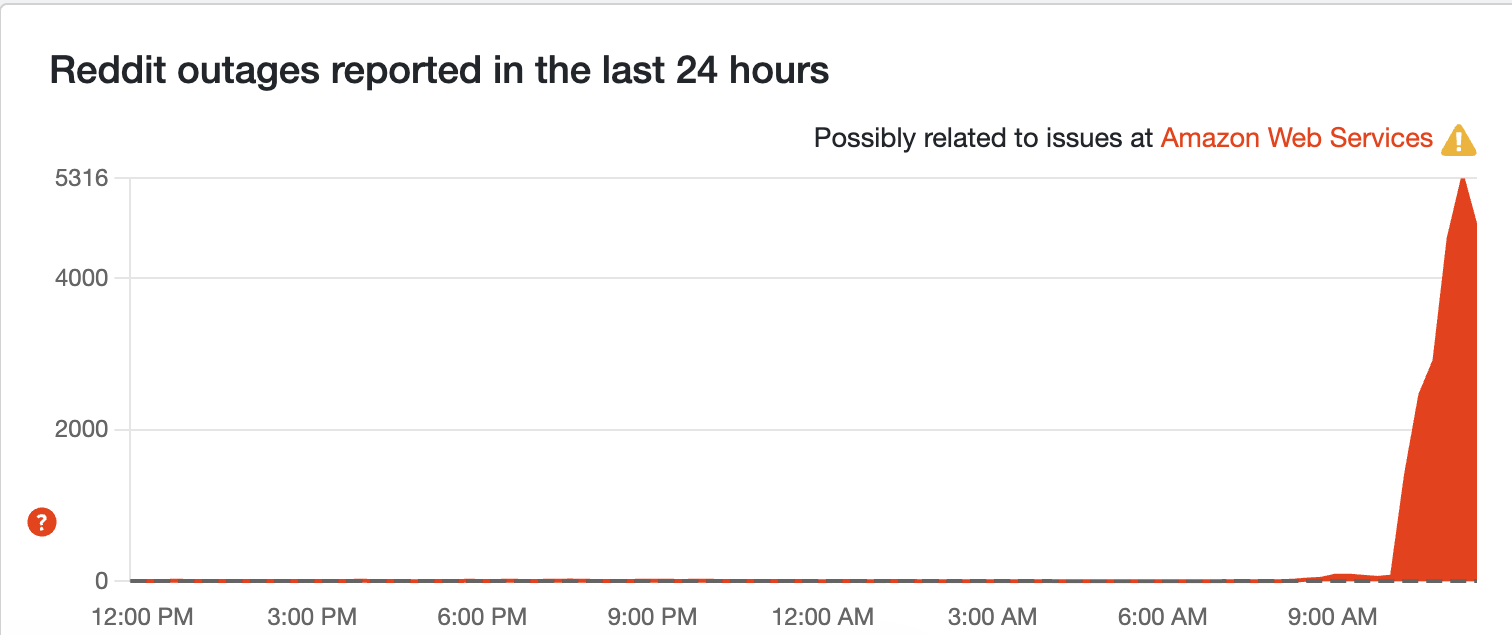
The issue has appeared as an incident report on Reddit's status page, and the Down detector reports have peaked. Something tells me AWS may have gotten around to looking at the Lambda and Cloudtrail problems.
Telecoms impacted?

This I didn't expect. BT in the U.K. does have a site that runs on AWS, which is now loading fine. But broadband problems are being reported and there's a big spike around it.
The physical layer of the broadband connectivity is not dealt with by cloud providers, but it does run the things like customer account management, billing and network intelligence (to keep things running). So something may have happened here.
NOT STARBUCKS!?
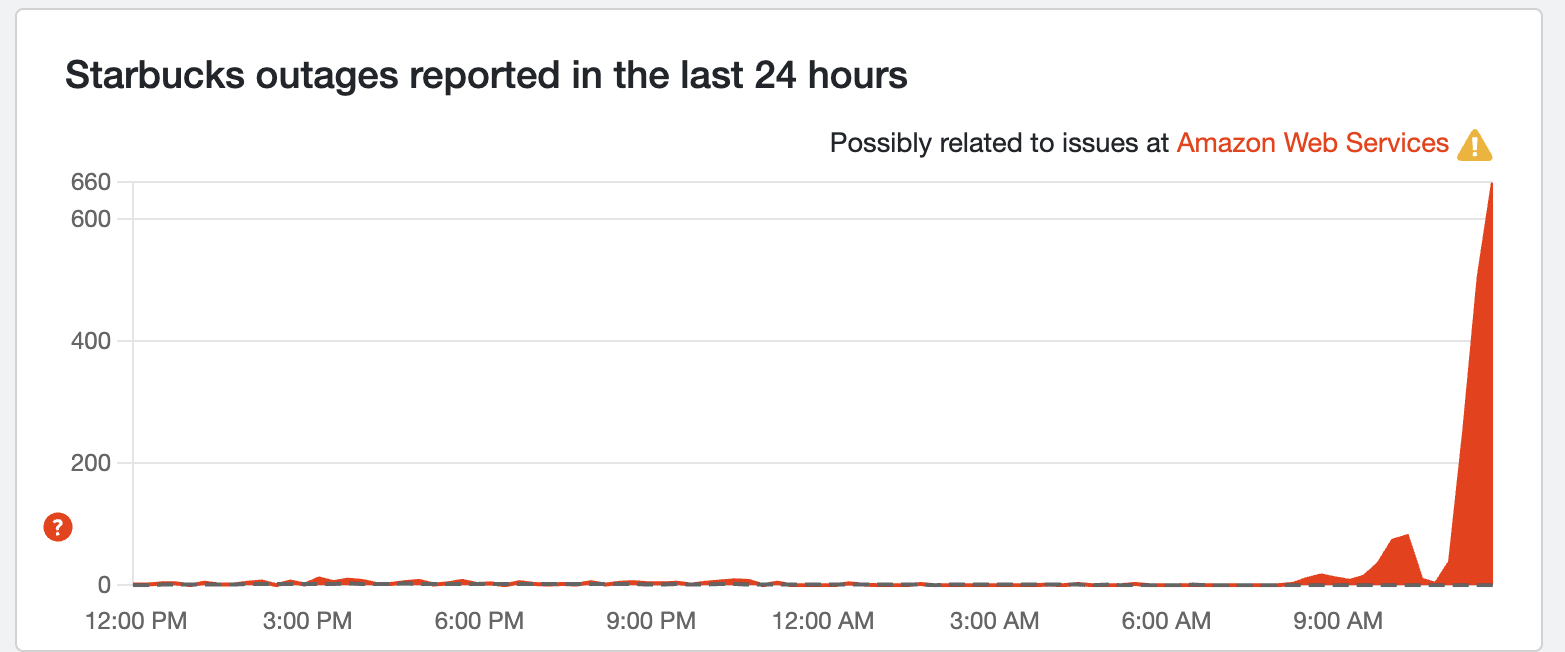
For those looking to redeem points on their monday morning caffeine infusion may come a cropper, as the Starbucks app is down, due to the AWS issues. The fix has been deployed, but Amazon's now going through a backlog of smaller issues to fix these smaller disruptions.
Reddit outage reports down nearly 50%
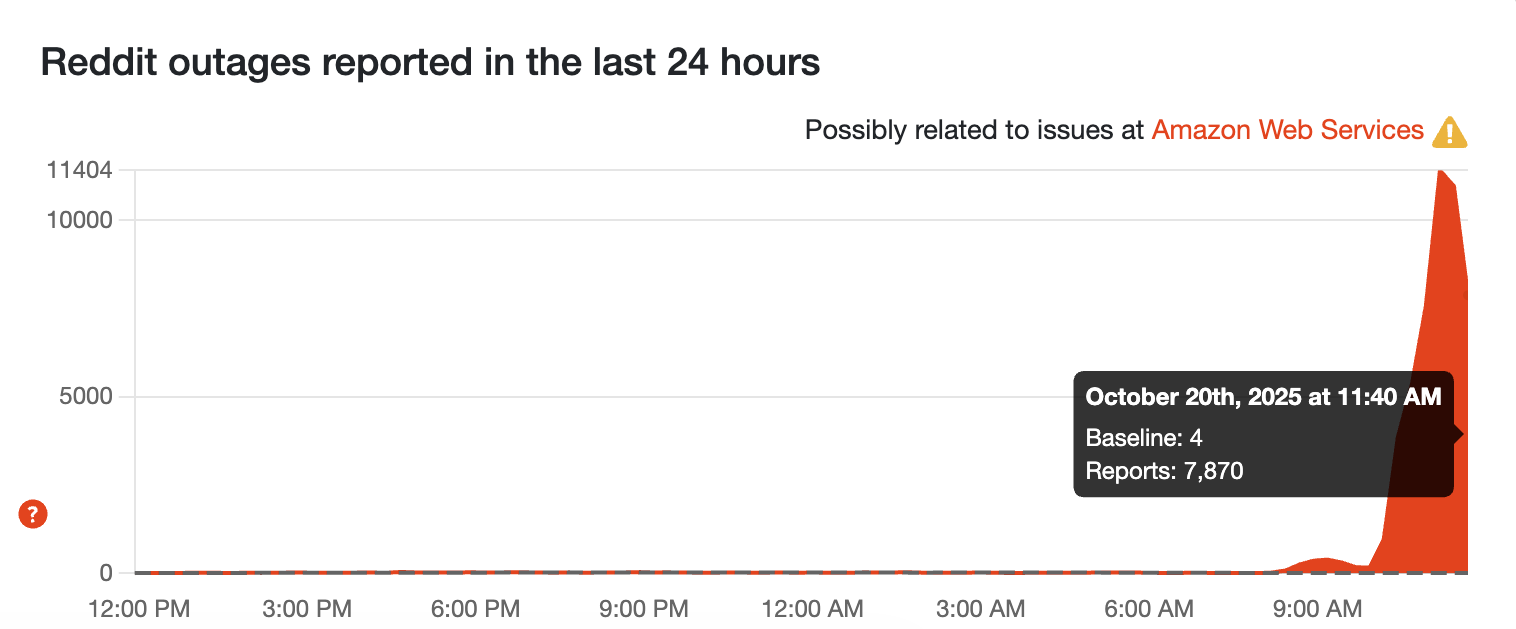
This is an encouraging sign. Still a long way away from the baseline, but that's a big dip in a short amount of time!
Ring still seeing major issues
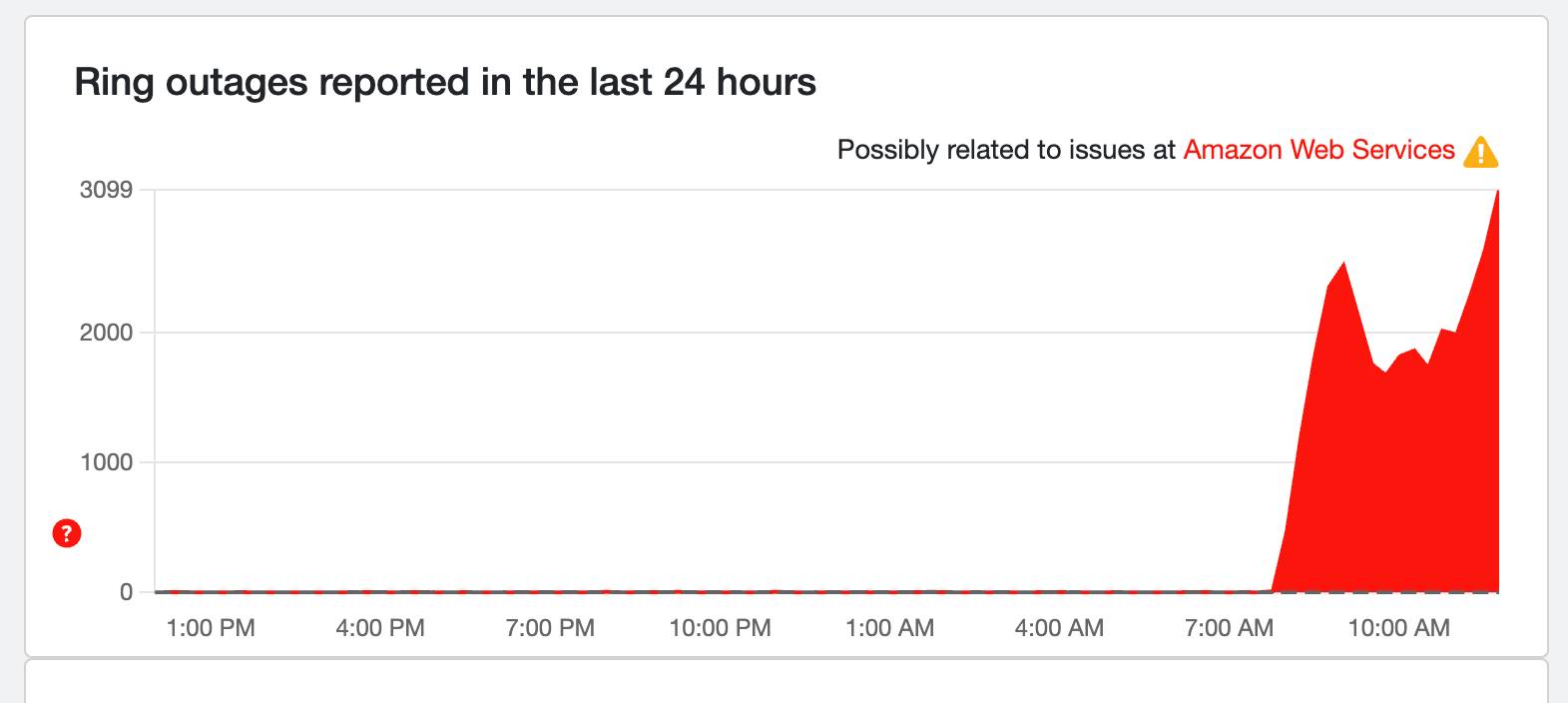
While some services like Reddit are getting fixed, Ring outage reports are on the rise, now at 3,296 as of writing. Hopefully, we'll see that number drop like the many other services right now.
AWS outage: All the sites and services affected

Over 40 services have been affected by the Amazon Web Services outage, which shows just how important the platform is for many different brands. Everything from Amazon, such as Alexa and Prime Video, to Snapchat and Strava went down, but fortunately, many of these services appear to be coming back to normal.
“When AWS sneezes, half the internet catches the flu. Outages like this cause frustrated users, but also triggers a domino effect across payment flows," Monica Eaton, Founder and CEO of Chargebacks911 and Fi911 commented. "Failed authorizations, duplicate charges, broken confirmation pages, all of that fuels a wave of disputes that merchants will be cleaning up for weeks. And once a customer files a dispute, you are already on the back foot.”
Here's a list of all the services affected:
- Amazon (including Alexa and Prime Video)
- Apple Music
- Blink
- Chime
- Coinbase
- Delta
- Duolingo
- Epic Games Store
- Fanduel
- Fortnite
- HBO Max
- Hinge
- Life 360
- Lyft
- McDonalds app
- Microsoft Teams
- My Fitness Pal
- Office 365
- PlayStation Network
- Pokemon Go
- Ring
- Roblox
- Roku
- Signal
- Slack
- Snapchat
- Square
- Starbucks
- Steam
- Strava
- Ubisoft Connect
- Venmo
- VR Chat
- Wordle
- Xbox
- Xero
- Zoom
Apple Music, Zoom back on the rise
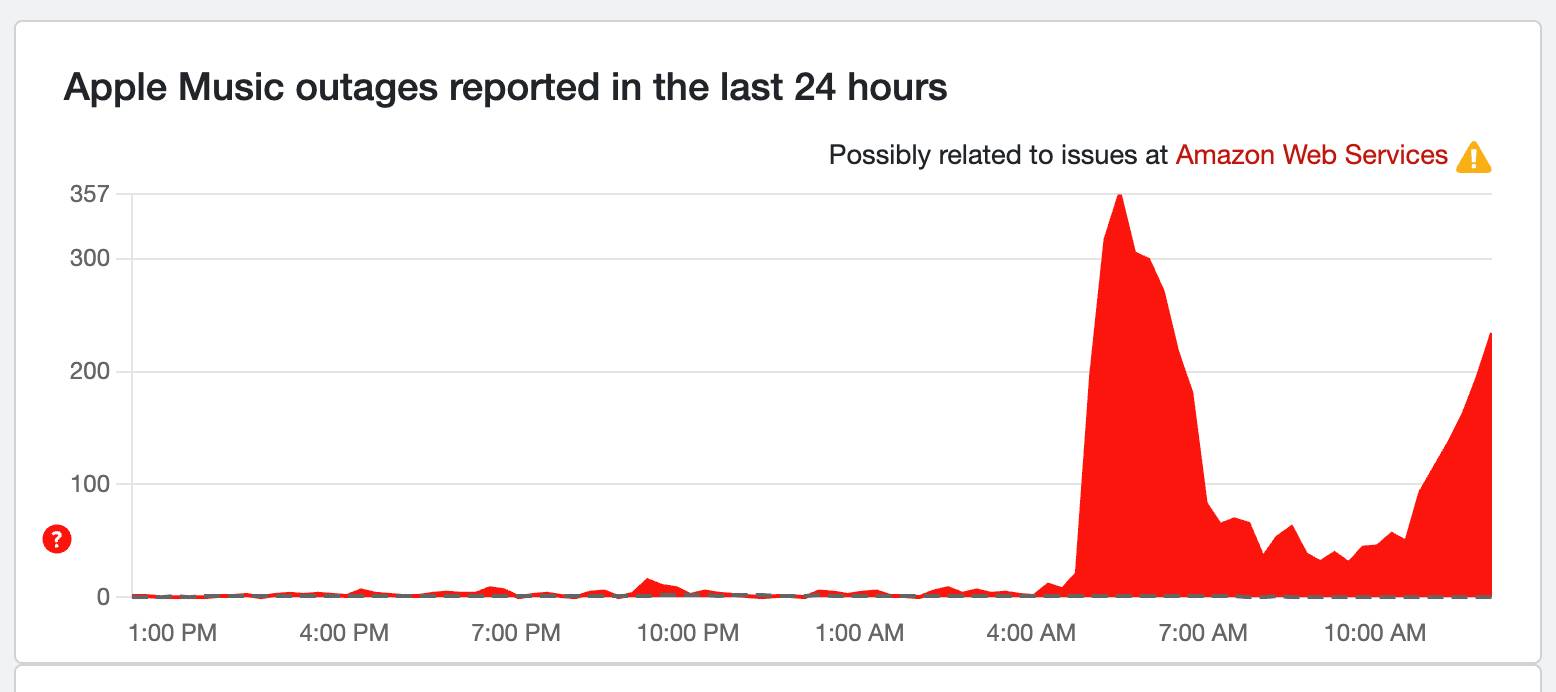
Apple Music is back on the rise with over 250 reports, but this isn't as bad as other services have been (Ring is still on the rise, too). Even Zoom on Down Detector is starting to see a spike again. It isn't all completely fixed, but as Amazon confirmed, AWS services should be coming back to normal. We'll keep you posted!
Amazon 'continuing to work towards full recovery'

In its latest update, Amazon has stated: "We are continuing to work towards full recovery for EC2 launch errors, which may manifest as an Insufficient Capacity Error. Additionally, we continue to work toward mitigation for elevated polling delays for Lambda, specifically for Lambda Event Source Mappings for SQS. We will provide an update by 5:00 AM PDT."
So, while AWS services are coming back to normal, there are still some issues to iron out. Hopefully, we'll see a full return to form in the next update.
Still some issues with AWS
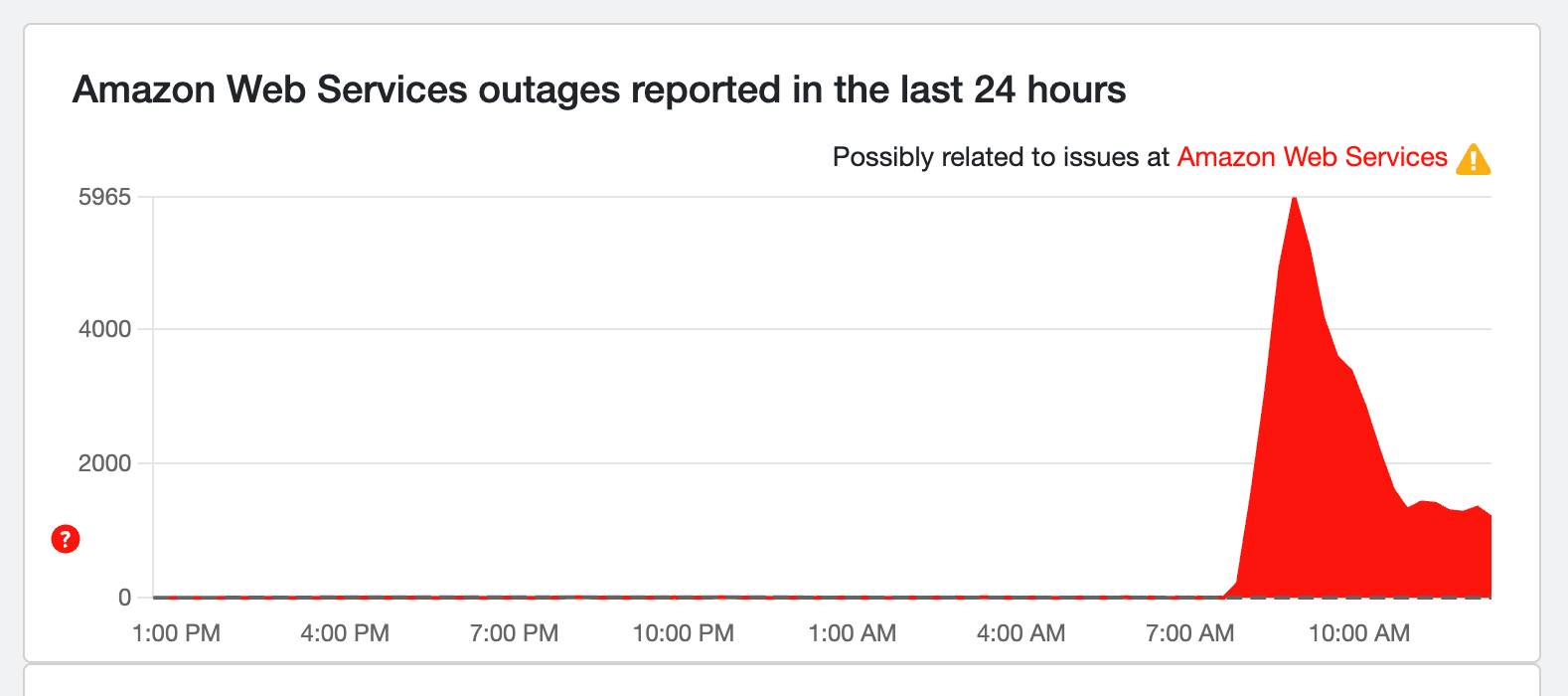
It's clear that AWS is still working on the issue, with Ring and Chime now seeing a spike in outage reports. Down detector shows that while reports have gone down, there are still problems to iron out!
Ring, Chime outage on the rise
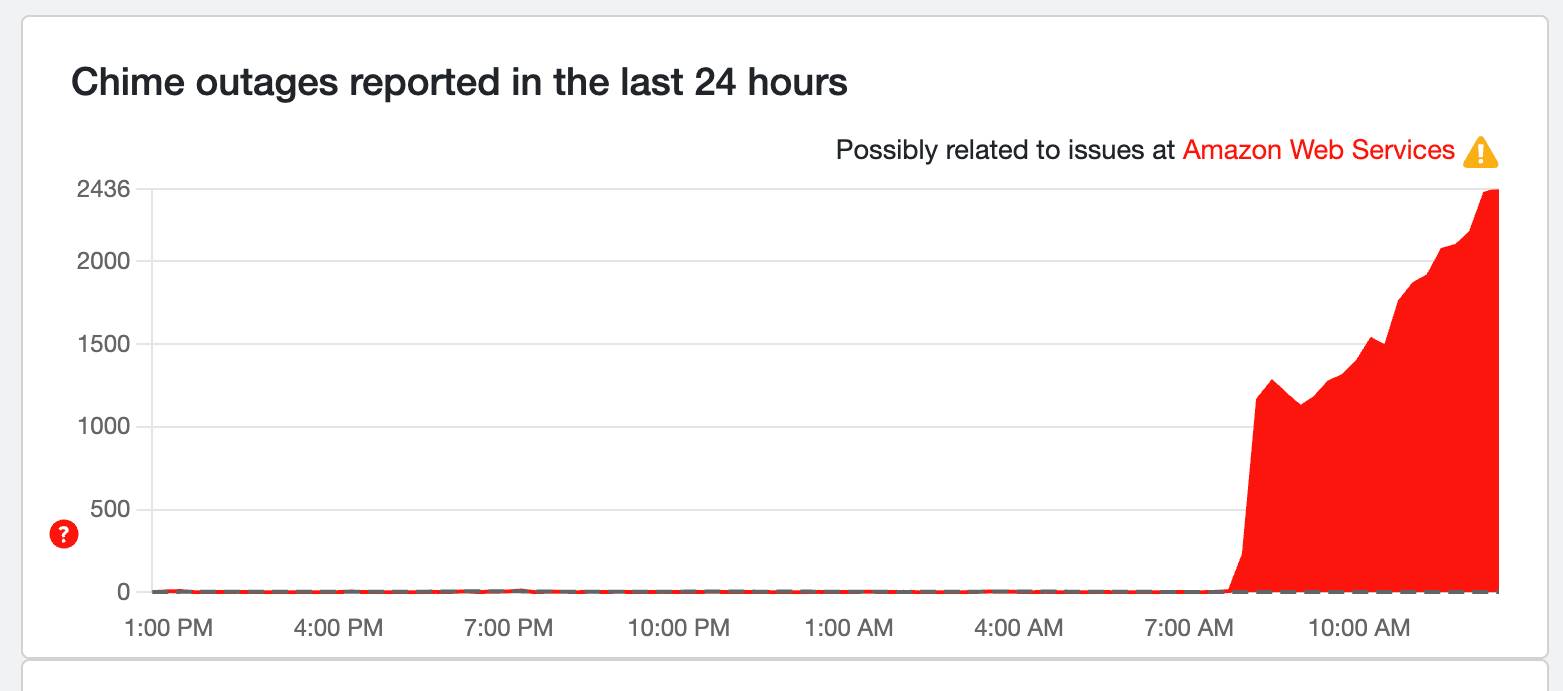
Chime and Ring are continuing to see increased outage reports, according to Down Detector, with over 4,000 reports currently. This shows the issue isn't fixed completely just yet.
As per the AWS status page, the latest update states: "AWS features that depend on Lambda’s SQS polling capabilities such as Organization policy updates are also experiencing elevated processing times."
This could be the problem causing services like Ring and Chime to be down.
Chime is still 'continuing to monitor for any further issues'
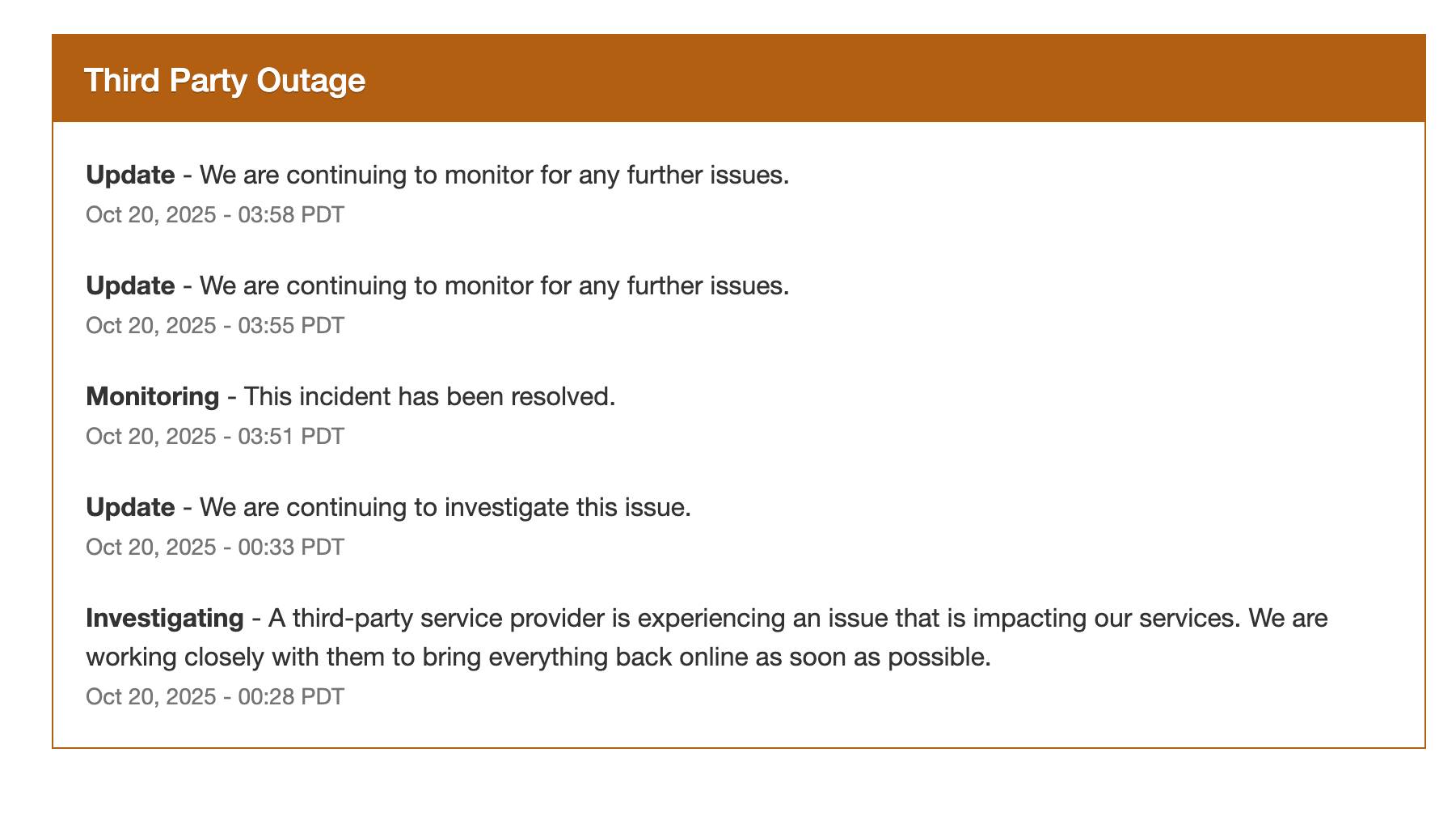
As per Chime's status page, the service is still experiencing outages. That includes its website, mobile app, MyPay feature and more. While Chime states the incident has been resolved, it's still experiencing issues with reports on Down Detector on the rise.
For now, Chime is "continuing to monitor for any further issues."
Multiple Ring systems are still down
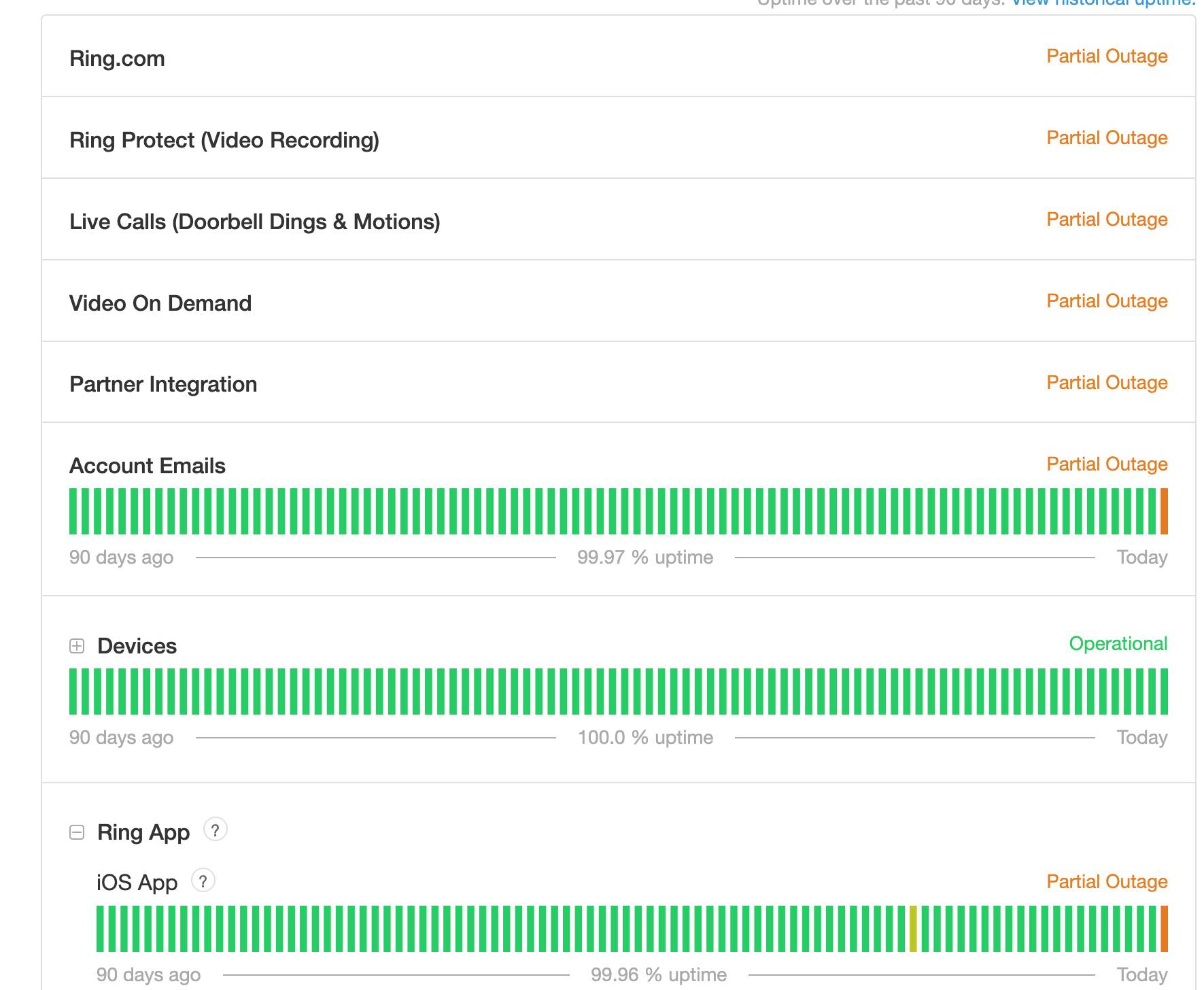
Along with Chime, Ring is experiencing multiple issues with its systems. According to its status page, Ring.com, Ring Protect, Live Calls, Video On Demand and more are seeing a partial outage, and this is backed up by the continued rise in reports on Down Detector.
Starbucks finally seeing a fix?
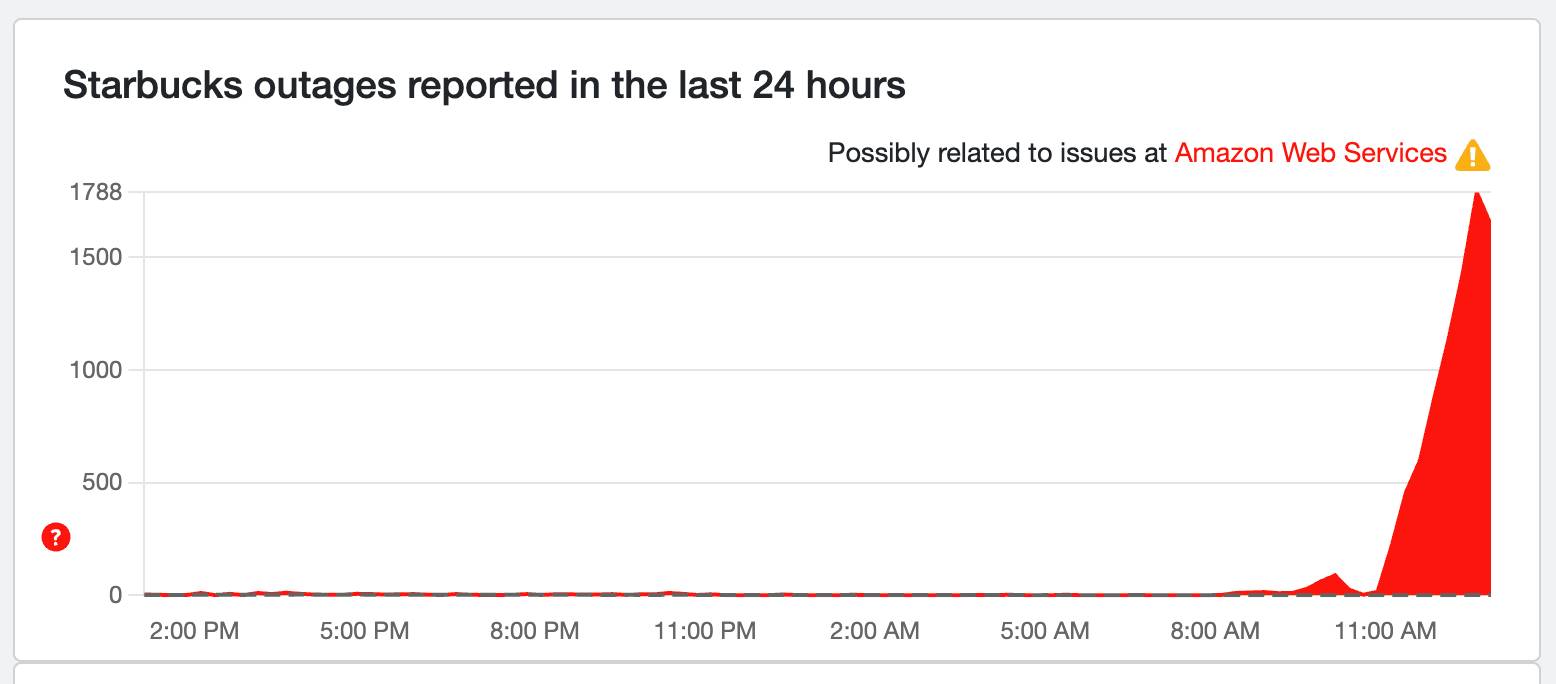
Even those morning coffees (to redeem points, anyway) from Starbucks were being affected by the AWS outage! It's been on the rise, but now it's finally seeing a dip in reports, which is hopefully signs that a fix is now in place.
Snapchat going through another spike?
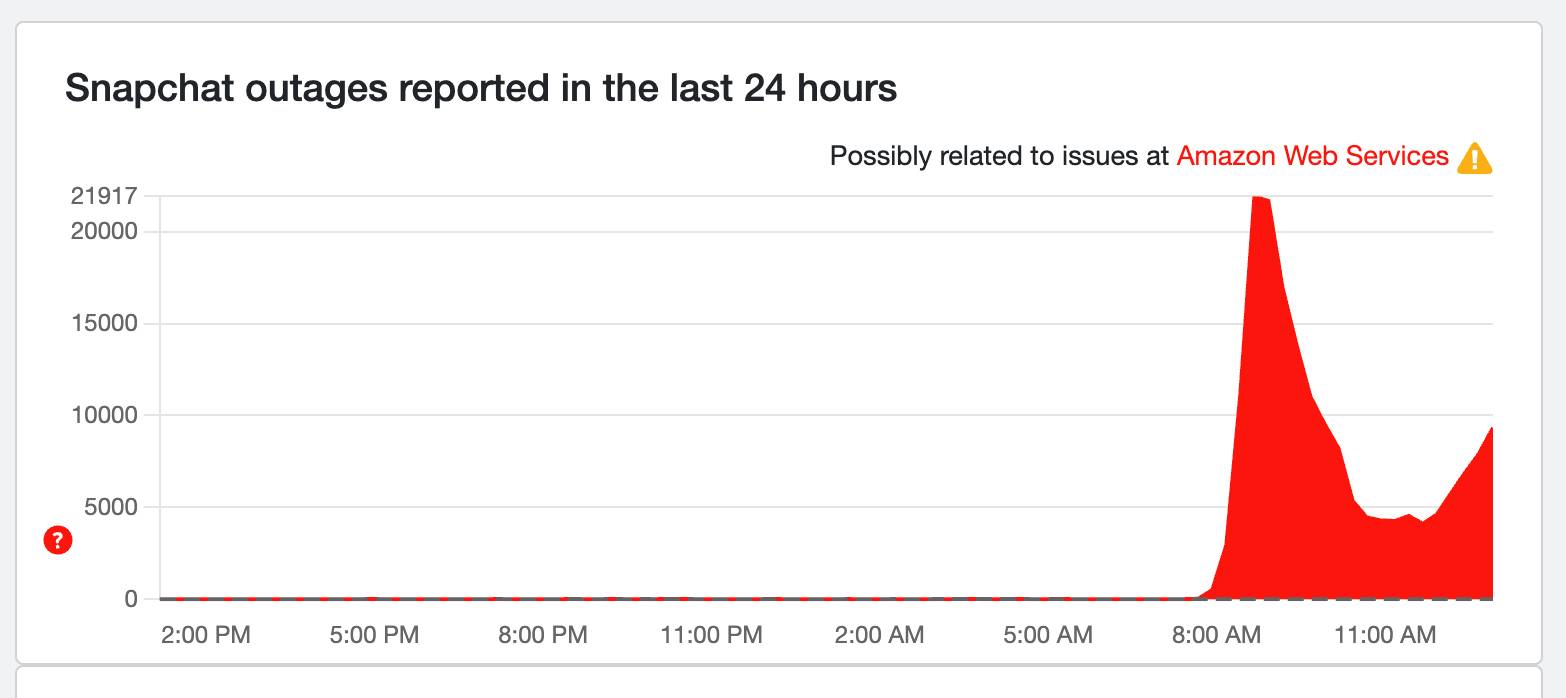
Turns out Snapchat is going through yet another spike! On Down Dectector, Snapchat has seen a major dip after AWS has been reportedly fixed, but it's now seeing a steady rise back up to nearly 10,000 reports.
This rise started as of 8 a.m. ET / 1 p.m. BST, so it could be that East Coast users are now waking up to a wave of issues. Will that second-spike reach the heights of before? Here's hoping the fix will clear that issue right up.
You can find out more in our Snapchat outage live blog if that's the service you're focused on!
Ring is being fixed!
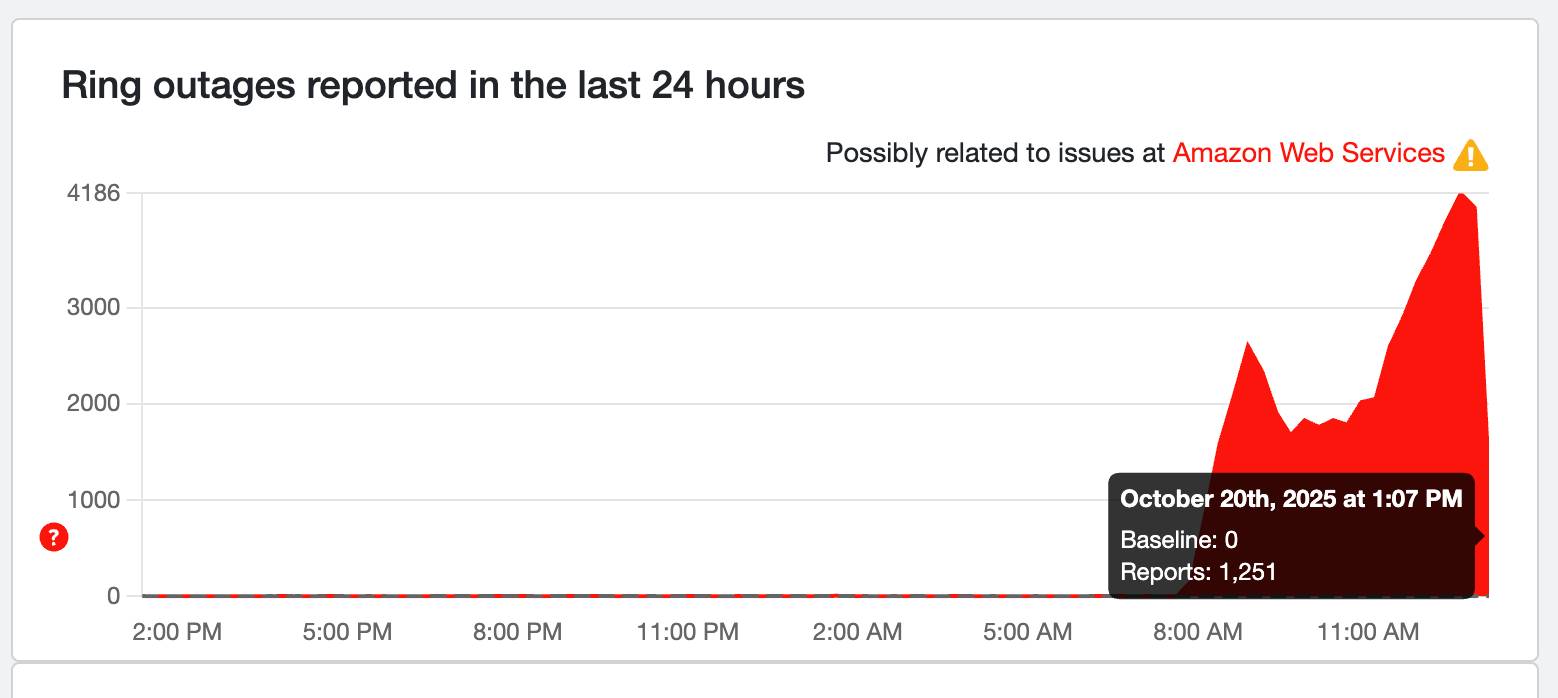
While Ring's support page shows there are still partial outages across its systems, Down Detector shows a steep decline in outage reports! Now under 1,000 (934 reports at the time of writing), that's a good sign that the service is coming back to normal (finally).
Amazon is still sorting out issues with AWS, so it's only a matter of time until we see all services work as they should. We're keeping track of how it looks, but in the meantime, it appears Ring and Chime are getting the fixes they need.
Chime is back up and running (it appears)

Along with Ring, Chime is seeing a massive decline in outage reports over on Down Detector, and according to its status page, all of its services are fully operational! That's a couple of services now on their way to see a full recovery, but we're not out of the woods just yet.
Snapchat continues to see a steady rise in outage reports, while other services like Zoom and Apple Music appear to still be experiencing some issues. Since AWS is still going through its fixes, we're sure to still see a few issues pop up. We'll keep you updated!
Is Reddit back up and running?
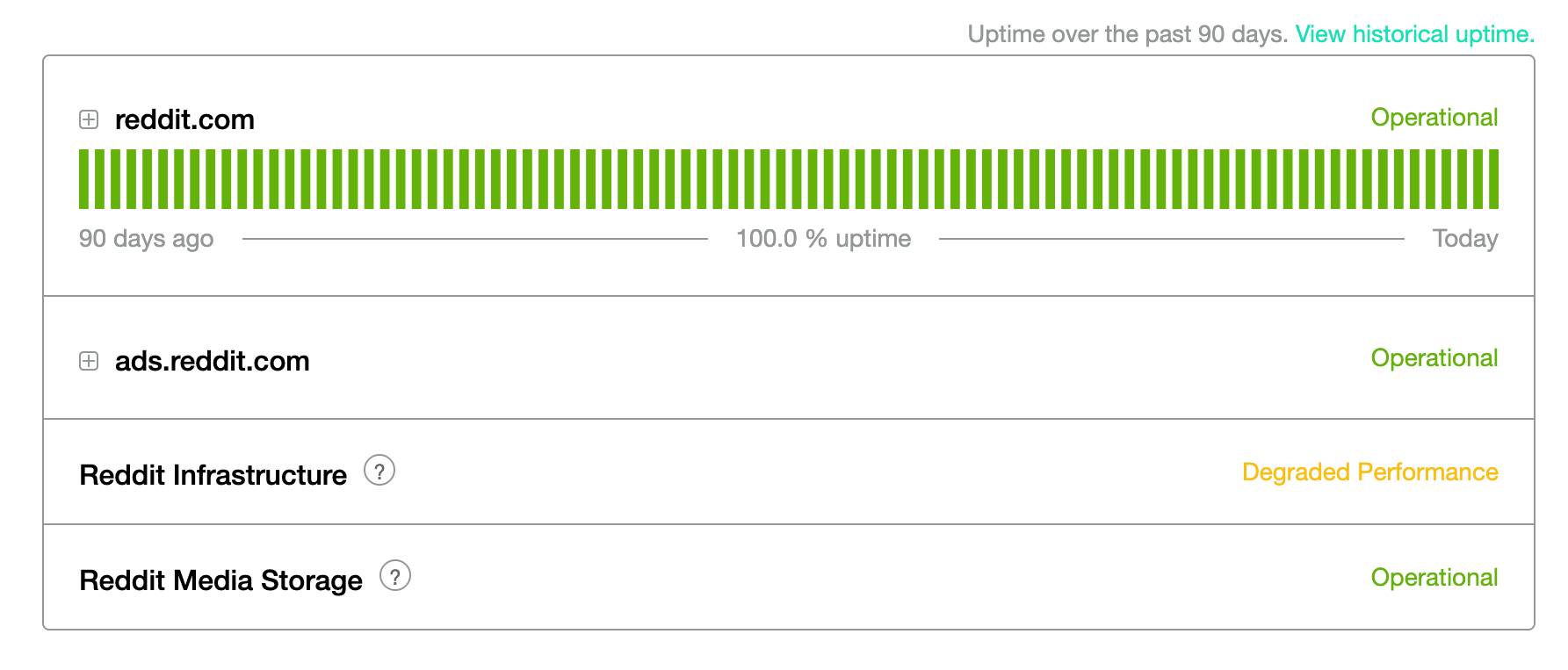
Reddit saw a big outage at around 5am EST / 10am BST, but it now appears to be fixed according to its status page. That said, the servers that support Reddit are still seeing performance issues, but at the very least, reddit.com is operational now! With just a few lingering outage reports on Down Detector.
At the very least, it works for me and the team. Will Snapchat see the same fixes soon? Here's hoping.
AWS outage: Over 1,000 companies affected
The AWS outage is massive, and to know just how big it is, there are over 1,000 companies affected by the Amazon Web Services issues this morning, as per a BBC report.
In fact, Down Detector noted that it saw 6.5 million reports globally, and that includes apps like Snapchat, Ring, Reddit, Starbucks and plenty more (find out all the apps and services affected by the AWS outage).
If you've been affected, you definitely won't be alone!
BREAKING: AWS 'making progress on resolving the issue'

Amazon has updated its AWS status page on the ongoing issues it's clearing up, stating: "We are making progress on resolving the issue with new EC2 instance launches in the US-EAST-1 Region and are now able to successfully launch new instances in some Availability Zones. We are applying similar mitigations to the remaining impacted Availability Zones to restore new instance launches. As we continue to make progress, customers will see an increasing number of successful new EC2 launches."
This essentially means that services should soon see a return to form, as we've seen with Chime, Starbucks and other services that saw continued issues. That should mean that Snapchat will see some fixes soon (fingers crossed), as it's now see a second spike of reports on Down Detector.
More updates on AWS will be on the way soon, and we'll be keeping track!
BREAKING: Wordle joins Snapchat in a second spike
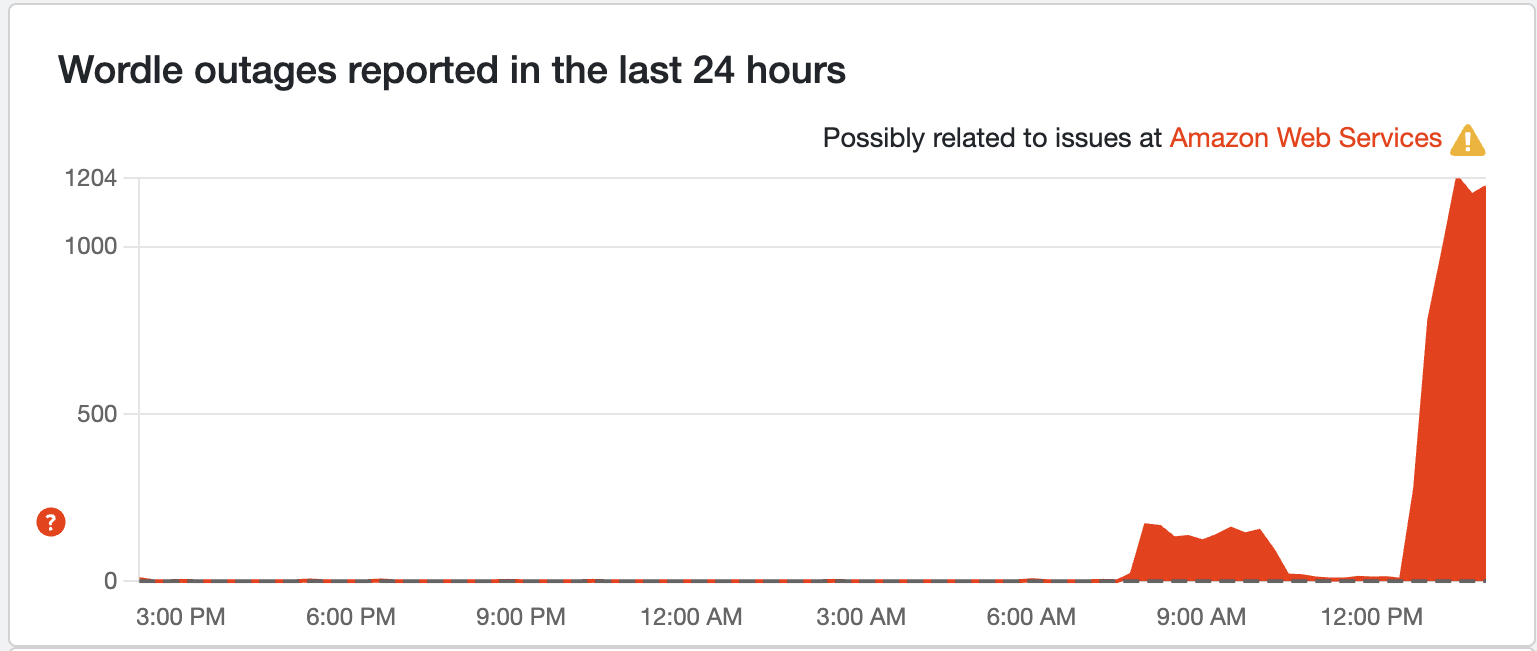
I hope you managed to get your Wordle answers in to keep your streak alive, because it looks like the game is down again! Users are struggling to login to play today's puzzle.
This joins the second spike of outages led by Snapchat.
Apple Music's second spike exceeds first outage
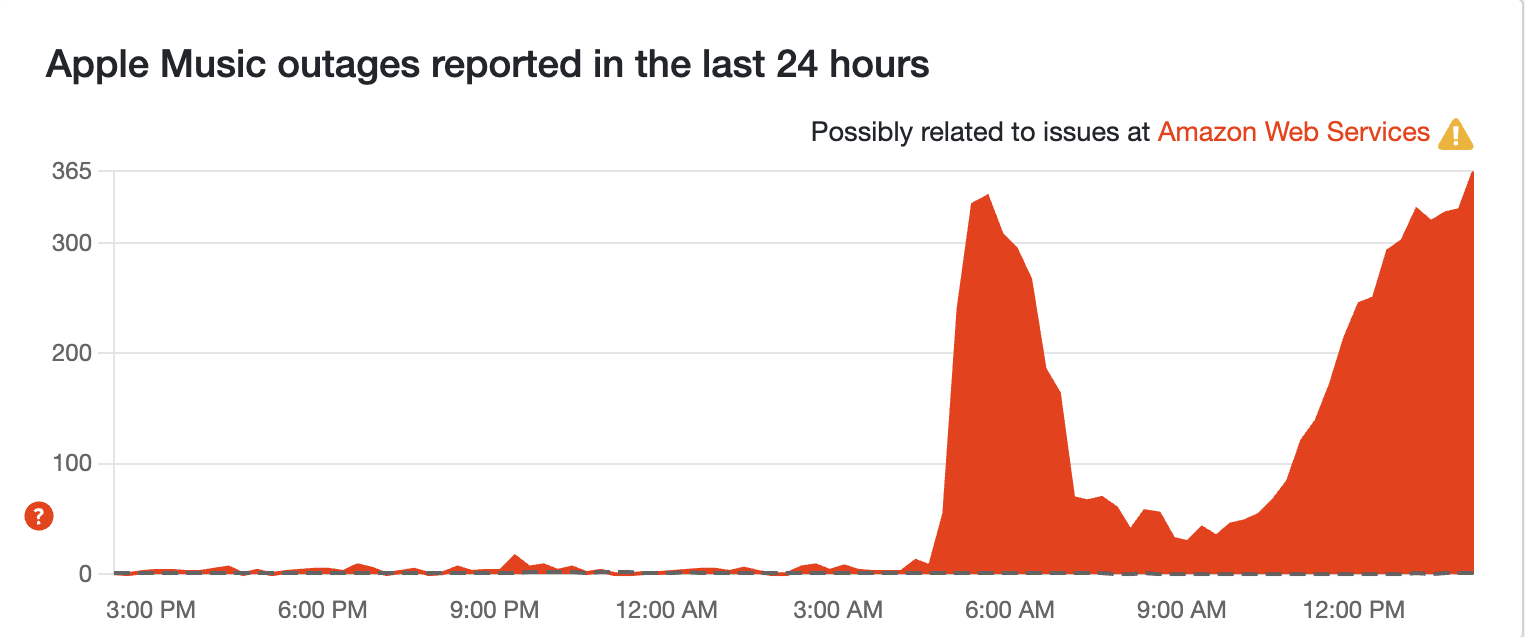
Uh oh... The peak around the first stint of the AWS outage hit 359. Now it's peaked again at 364 with users reporting music streaming problems. Issues seem to be localized to New York and Los Angeles right now, but could be more widespread as the U.S. wakes up and tries to play their get up playlist!
BREAKING: Huge spike of outages on Instacart
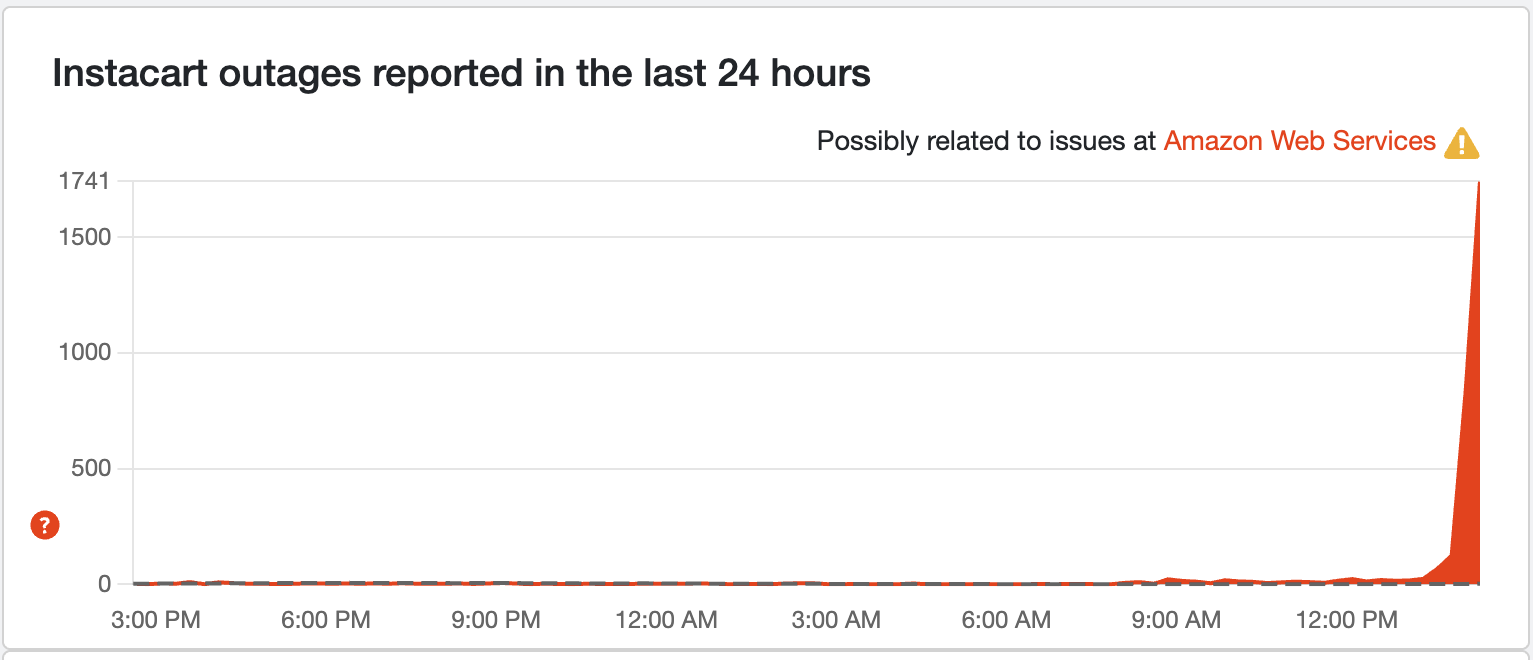
Online grocery shopping might be off the cards for you atm, as a huge jump in Instacart outage reports has just occurred. We're trying to get to the bottom of what's happened here, but everything seems to be tying back to the EC2 instance launches not being effective or scaling to a larger pool of users.
A new statement from Amazon is IN

OK, so, we're all a bit confused because Amazon tells us its fixed, but then services are still experiencing problems. Now there's an update, and it paints a bit more of a picture.
Basically, what Amazon is trying to say here is that while the DNS issue has been fixed (the digital phonebook of the internet now directs people to the right places), the tool that connects people is still jammed, and are causing massive slowdown across all of its sites.
This is why services are being rate limited, to stop the system from crashing and allow the existing problems to fully clear. This is a temporary cap on how many people can go to certain sites — like a bouncer at a crowded Halloween party (I'm dressing up as Peacemaker btw). This should stop the system from crashing and allow existing problems to fully clear.
Pinterest outages spike
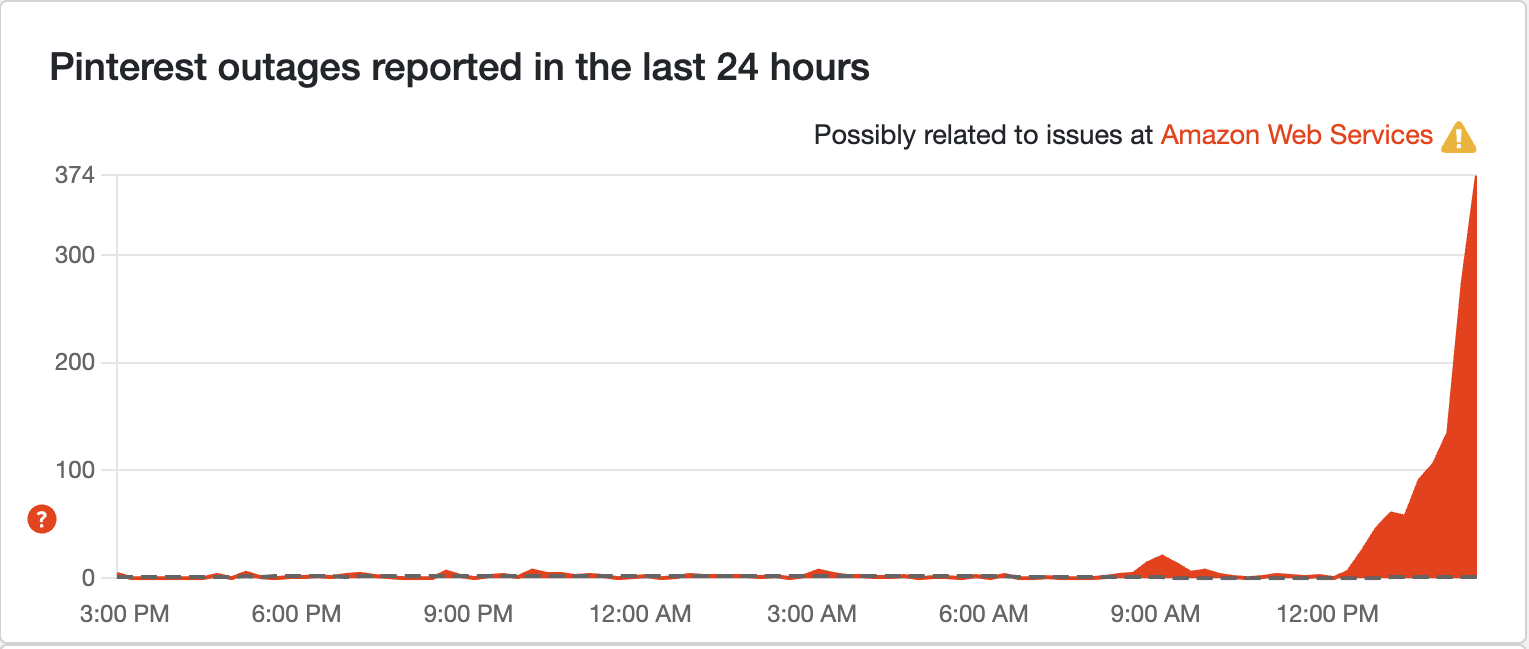
Looking for tasteful living room ideas or inspirational quotes written entirely in helvetica? That's not going to be possible for a lot of you, as the rate cap has seemingly spiked outage reports on Down Detector about Pinterest.
Apple system status suggests Music is back... Let's see
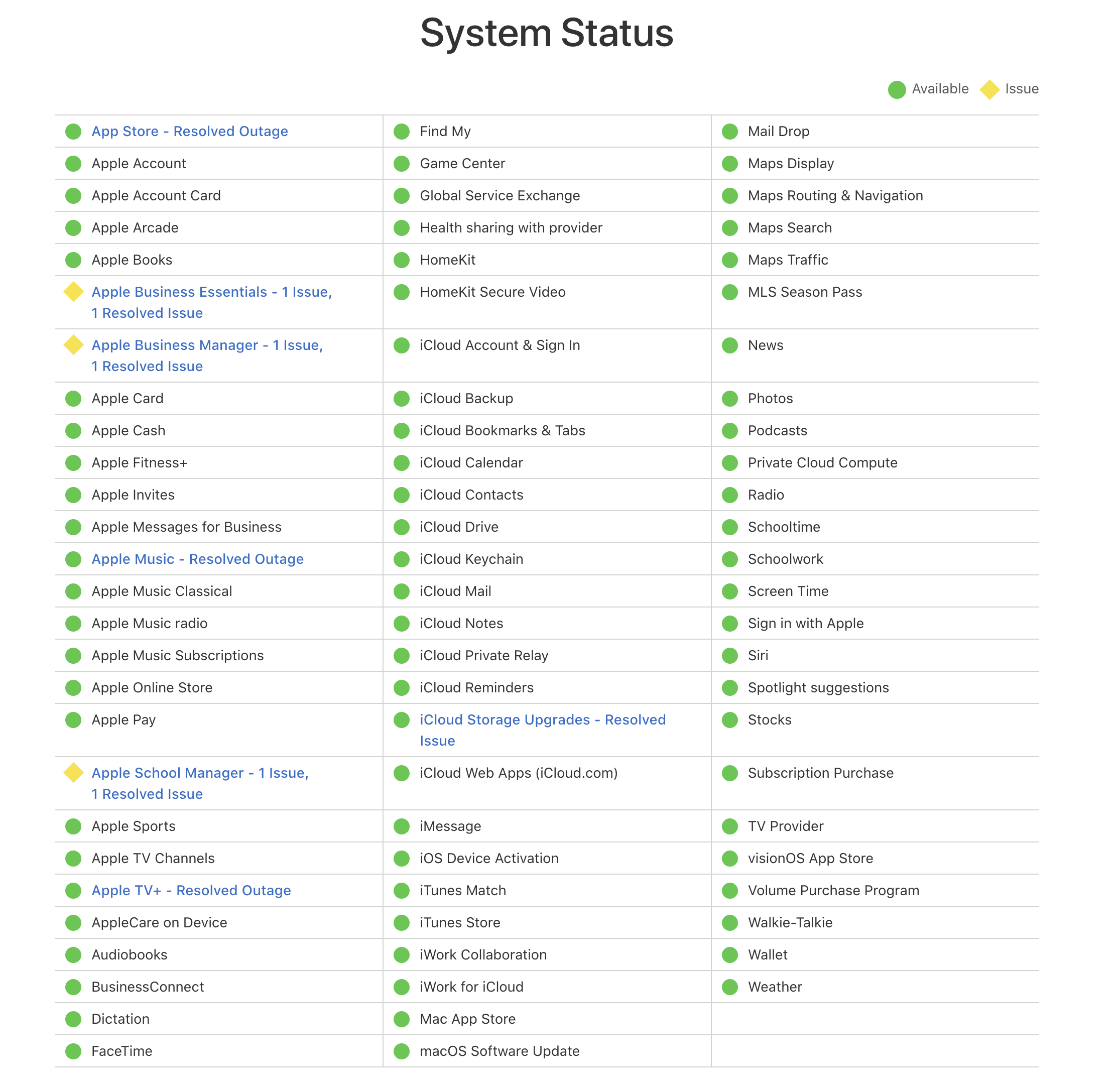
Even though Apple Music outage reports continues to grow, Apple itself is confirming that the outage has been resolved. We'll see whether this is true in a few minutes if that curve goes down.
Also worth noting if you're having business, school management or iCloud issues, the Cupertino crew are already looking into these too.
BREAKING: Tidal is down
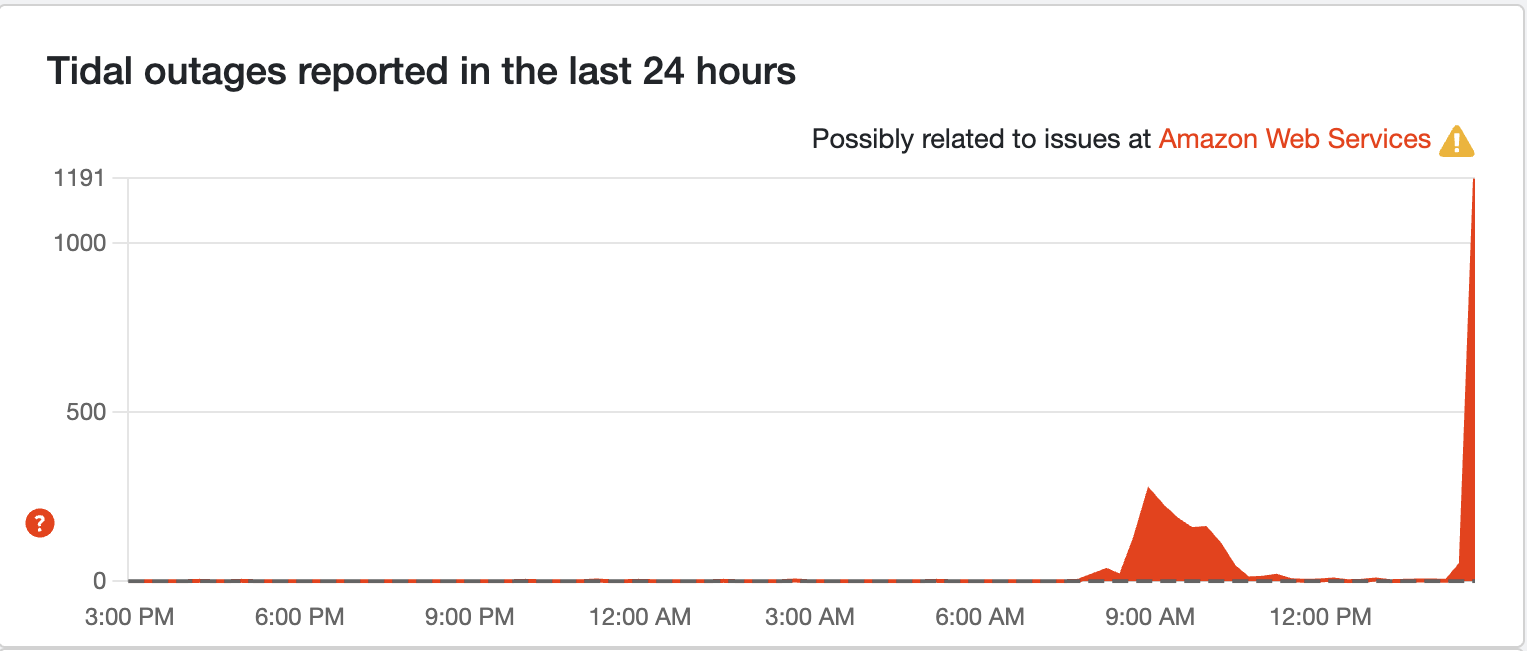
This spike makes the potential Apple Music outage look like a minor speed bump! Over 1,000 reports in the past few minutes, with 54% of people across the U.S. reporting audio streaming issues. This, again (I believe) is probably down to the rate cap that AWS has put in place to ease pressure while fixes are implemented.
AWS problems have exposed how dependent the UK has become on "fragile cloud infrastructure"

While in the U.S. there's been some big outages of banks and grocery services, the U.K. has seen outages of Government sites like HMRC (the bit that deals with tax and revenue) and the overall Government website.
This is incredible problematic, as Cybersecurity Expert Christian Espinosa from Blue Goat Cyber talks about.
“The widespread outage that affected Amazon Web Services and major platforms across the UK is a stark reminder that our digital world is built on a surprisingly fragile foundation. Cloud concentration, where a handful of providers host most of our critical systems, creates a single point of failure," Espinosa comments.
"When one data region or provider goes down, ripple effects hit everything from retail and finance to logistics and communications. For UK businesses, this affects security more than prductivity. During outages, normal safeguards are often bypassed: staff use personal devices, backup credentials circulate, and attackers exploit the confusion."
BREAKING: A new update from Amazon confirms "significant" errors

When it rains, it pours for Amazon. The company has now confirmed some significant API errors (basically the way developers plug their work into), and connectivity issues across multiple services in the US-EAST-1 Region!
We're starting to see what that means across lots of services.
Yep, Venmo is down again

Oh boy, here we go again. With a ginormous spike of 4,440 outage reports on Down detector, Venmo is down again!
As we've seen from the past one, your money should be safe if you have any in transit. And you can report anything that seems off with your transfers once you're back on. But this again seems to be down to that rate cap. No update from AWS yet on lifting it!
More issues confirmed by Amazon

Another update has just dropped on the AWS status page, and it's more issues creeping up. "Network connectivity issues" are plaguing the web services platform, so others will see them too. But "early signs of recovery" are being spotted, as the root cause continues to be investigated.
This one is a big problem
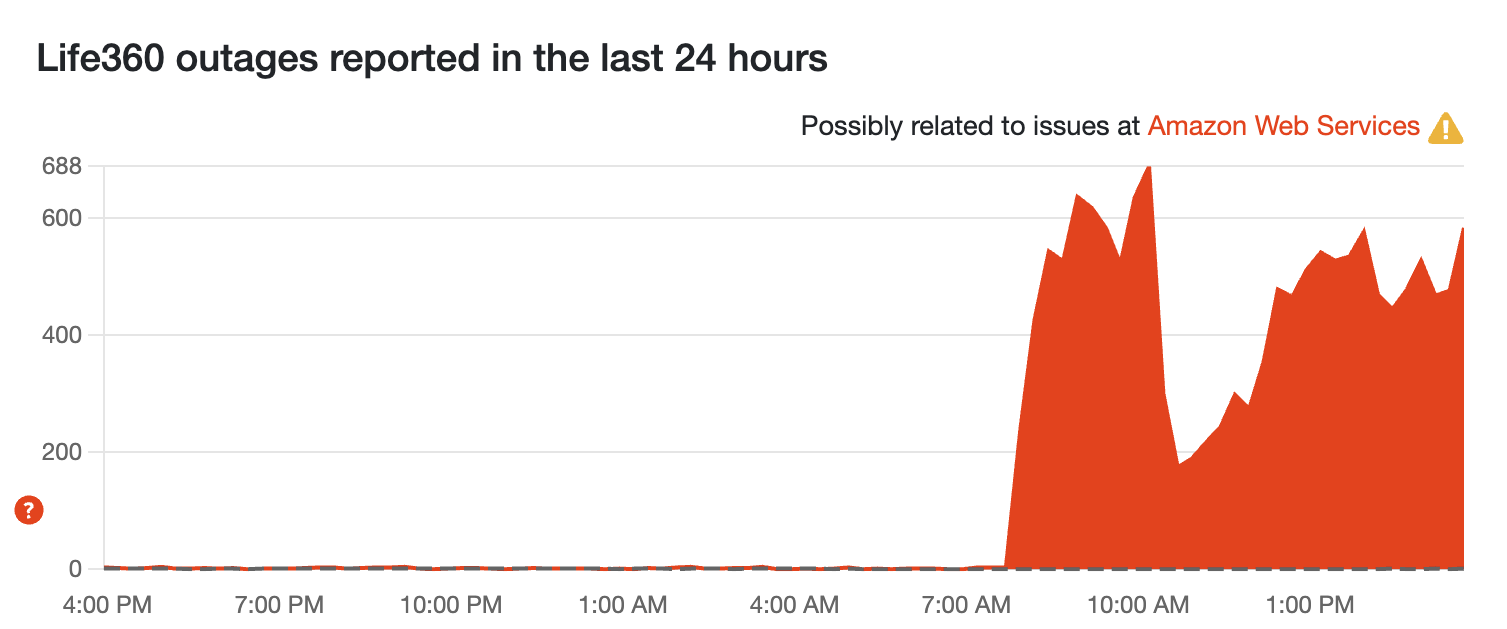
For those who aren't in the know, Life360 is a location-sharing app that families and friends use in close circles to see each other's live locations on a private map. This is good for establishing designated meeting points, and giving people an SOS button for emergencies, while also ensuring people get home safe.
This service (unfortunately) is on AWS, and the app is down for a lot of people. For those who are just looking after their loved ones, this is incredibly problematic.
Pinterest is on the rise
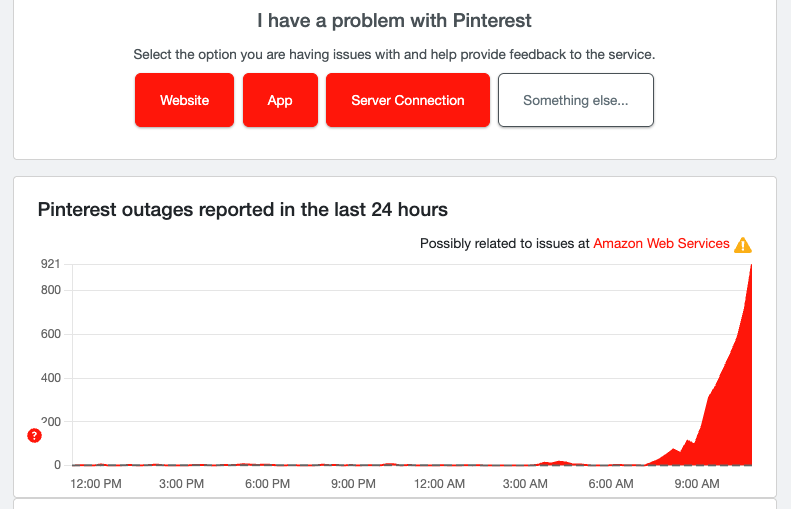
Pinterest, another popular social network, is seeing a rise in reports. Like many of the big outages, we have to assume this one is connected to AWS and the ongoing issues it's having. It really puts into perspective how much we rely on Amazon Web Services to keep the internet chugging along smoothly.
A sudden Verizon spike
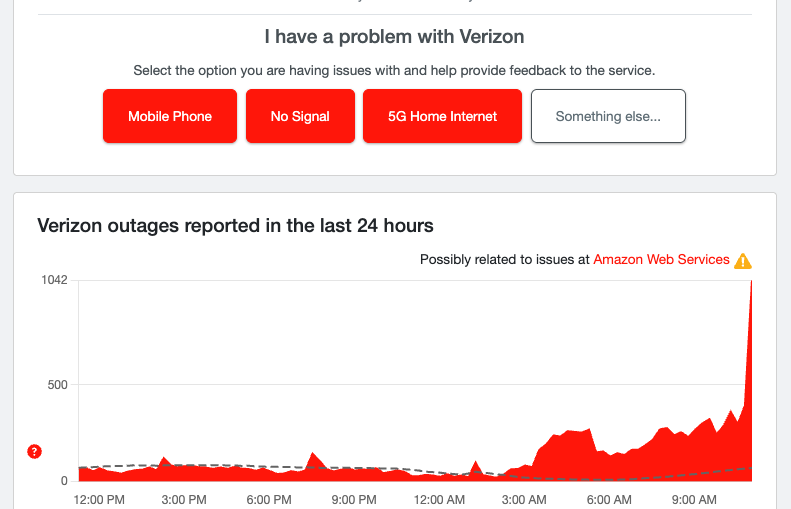
It looks like some people are experiencing issues with Verizon, though it's unclear whether it's landlines or mobile at this time. We also don't know if this one is linked to AWS or something else entirely, but we'll certainly keep an eye on it either way.
A small update to say... not much

AWS released a status update that doesn't offer much clarity. In short, the company acknowledges the issue and is investigating, which was already the assumed situation.
"Oct 20 8:04 AM PDT We continue to investigate the root cause for the network connectivity issues that are impacting AWS services such as DynamoDB, SQS, and Amazon Connect in the US-EAST-1 Region. We have identified that the issue originated from within the EC2 internal network. We continue to investigate and identify mitigations," reads the AWS status page.
Higher than the original
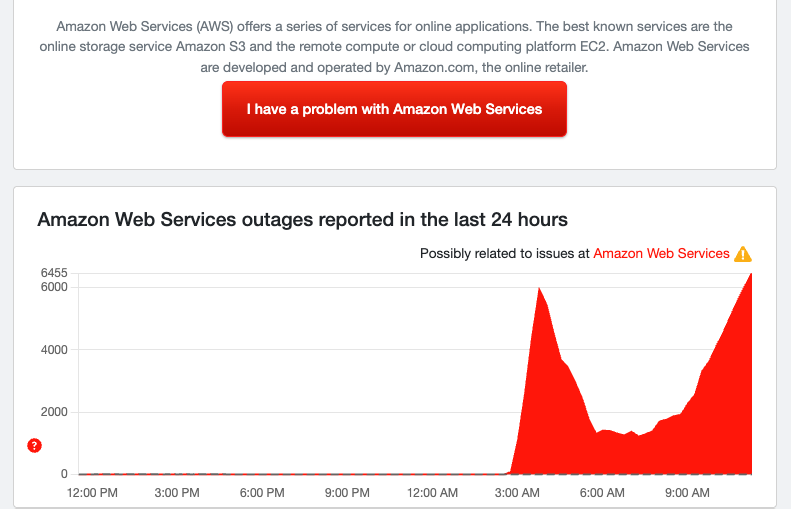
We're seeing more reports on Down Detector for AWS than when this first started. The previous peak was around 6,000, and now it's up to 6,400. It's clear this outage is going to last a while longer, but hopefully not for too long, as the internet is really struggling today.
How much is this affecting you?
Almost everyone is being impacted by this outage in some way, but we're curious how much it's messing with your flow. Vote in the poll above and let's see how much Tom's Guide readers are being put out by this AWS situation, which experts say could cost billions of dollars.
"The home delivery specialist Parcelhero says that, when a similar event happened last year at Crowdstrike, it cost $5.4 billion in losses for Fortune 500 companies and impacted a wide variety of companies globally," said Parcelhero’s Head of Consumer Research, David Jinks.
End in sight, maybe?

Amazon might have a solution on the horizon!
"We have narrowed down the source of the network connectivity issues that impacted AWS Services. The root cause is an underlying internal subsystem responsible for monitoring the health of our network load balancers. We are throttling requests for new EC2 instance launches to aid recovery and actively working on mitigations," the company said on its AWS Health Dashboard.
It doesn't sound like we're out of the situation yet, but we're getting closer, which is good news.
Peloton joins the outage
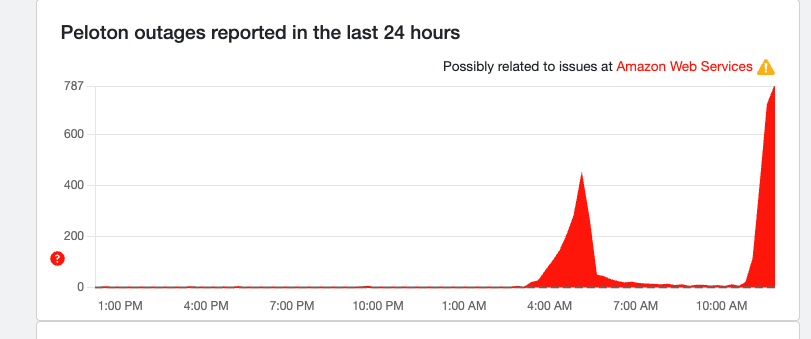
We're seeing a huge rise in reports for Peloton (relative to the size of the service). It's at almost 800 reports, which is a high number. Users are obviously having issues connecting the relatively costly exercise service.
AWS will have an update soon

"We have taken additional mitigation steps to aid the recovery of the underlying internal subsystem responsible for monitoring the health of our network load balancers and are now seeing connectivity and API recovery for AWS services. We have also identified and are applying next steps to mitigate throttling of new EC2 instance launches. We will provide an update by 10:00 AM PDT," reads the company's live blog.
The long-reaching issues with outages like this

The internet is dependant on AWS, which is fine most of the time. When something goes wrong, though, it's a scary reminder of how important one service like this is. Rob van Lubek, EMEA Vice President, Dynatrace spoke about that in a comment to Tom's Guide.
"Global incidents like this are a clear reminder of how dependent our world has become on software and digital systems operating as expected. Today's IT environments are far more complex and interconnected than many realize, so when an outage occurs, the ripple effects can quickly spread across industries and into people's daily lives," said Rob van Lubek.
“For large enterprises especially, the difference between disruption and recovery often comes down to visibility and speed - how fast an organization can pinpoint what's gone wrong, understand why, and act to restore service continuity. That level of digital resilience requires deep insight into how systems connect and where vulnerabilities might emerge, so teams can focus on what truly matters in a crisis," he continued.
Ok, now they're taking away my Wendy's
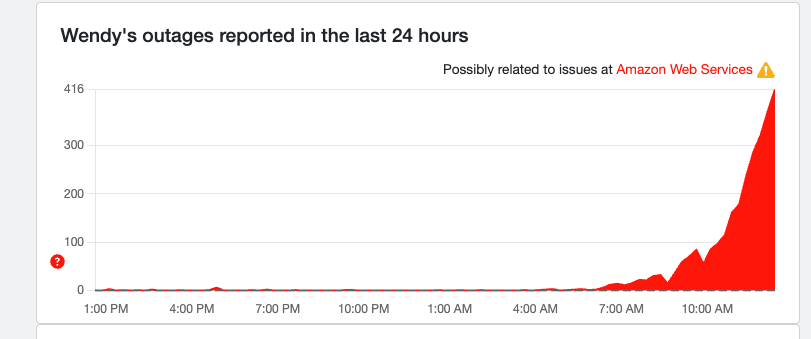
Half the internet is down, so it was only a matter of time until the fast food industry felt it. But why Wendy's?
The losses are huge

We're receiving a lot of interesting tidbits from different analysts talking about the far-reaching effects of this outage. One that stood out says that $75 million is being lost per hour that this outage continues — with Amazon itself taking more than $72 million of that figure.
The data comes from Tenscope, and here's what it shows in terms of losses for some of the major companies:
- Amazon: $72,831,050 per hour
- Snapchat: $611,986 per hour
- Zoom: $532,580 per hour
- Roblox: $411,187 per hour
- Fortnite: $399,543 per hour
- Canva: $342,466 per hour
- Slack: $194,064 per hour
- Reddit: $148,402 per hour
As far as how Tenscope reached this conclusion, the company says it used "last year's publicly available revenue data for the affected companies, divided by 8,760 to determine hourly revenue loss during the AWS outage."
AWS posts an update

AWS updated its status page, albeit a little late. The company said, "We continue to apply mitigation steps for network load balancer health and recovering connectivity for most AWS services. Lambda is experiencing function invocation errors because an internal subsystem was impacted by the network load balancer health checks. We are taking steps to recover this internal Lambda system. For EC2 launch instance failures, we are in the process of validating a fix and will deploy to the first AZ as soon as we have confidence we can do so safely. We will provide an update by 10:45 AM PDT."
Based on that, it looks like we're going to have to wait another 45+ minutes to see if anything major changes.
So many red bars

Zooming out on Down Detector is truly a sight to behold. Everything from gambling sites to social networks to videos games are dealing with outages because of these AWS problems. It's scary.
In case you missed it...
As of this writing, our quiz asking how much this outage is affecing you on a scale of 1-100 is a 81%. But there's still time to vote!
Amazon on a downswing
Amazon is seeing another downturn in reports. Could this be the beginning of the end or is just users no reporting outages as frequently. We'll continue to monitor.
AWS comments again

"Our mitigations to resolve launch failures for new EC2 instances are progressing and the internal subsystems of EC2 are now showing early signs of recovering in a few Availability Zones (AZs) in the US-EAST-1 Region. We are applying mitigations to the remaining AZs at which point we expect launch errors and network connectivity issues to subside," reads the company's latest status update.
More of the same...
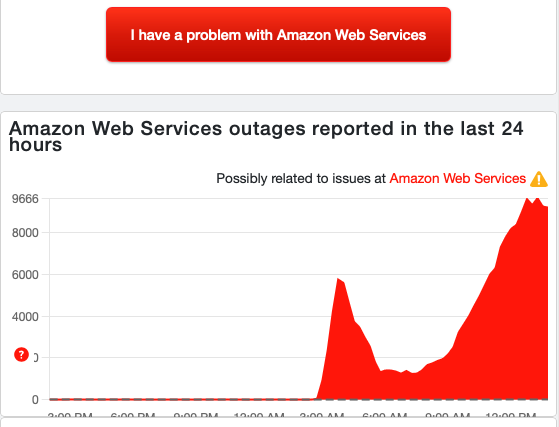
Unfortunately, there isn't much new to report. AWS is hovering a little below 10k reports as of this post, which is where it has been for the last couple of hours.
Next AWS update
Amazon says its will post another update by 11:30 am PDT (2:30 EDT), so we'll learn more soon. Hopefully it's good news!
And AWS says...
There seem to be some improvements happening, based on the latest comment from AWS.
"Our mitigations to resolve launch failures for new EC2 instances continue to progress and we are seeing increased launches of new EC2 instances and decreasing networking connectivity issues in the US-EAST-1 Region. We are also experiencing significant improvements to Lambda invocation errors, especially when creating new execution environments (including for Lambda@Edge invocations). We will provide an update by 12:00 PM PDT," reads the status page.
Which service is hurting you the most?
With so many services affected by this outage, it's hard to know which one is hitting our readers the most...
So we made a poll to find out! Let your voice be heard and tell us which AWS outage is hitting you the hardest. Are you on an epic Snapchat streak? Do you need to get a last-minute birthday present from Amazon? Money stuck in Venmo? Is it something else entirely? Vote in poll and we'll come back with results later on!
No update from AWS
The AWS Service Health page promised an update at 12 pm Pacific, but as of this writing (12:15 pm), there has yet to be an update.
The previous update from around 11:22 am, indicated that things were starting to turn around, albeit slowly.
Color me wrong
Welp, as soon as we posted that last update, AWS dropped their own.
So, what are they saying now?
According to the most recent update, they "continue to observe recovery across all AWS services." It does not that some customers may still face "intermittent functions errors."
This does seem reflect a decrease in reports on Down Detector across many of the affected services and AWS itself.
Ring services down
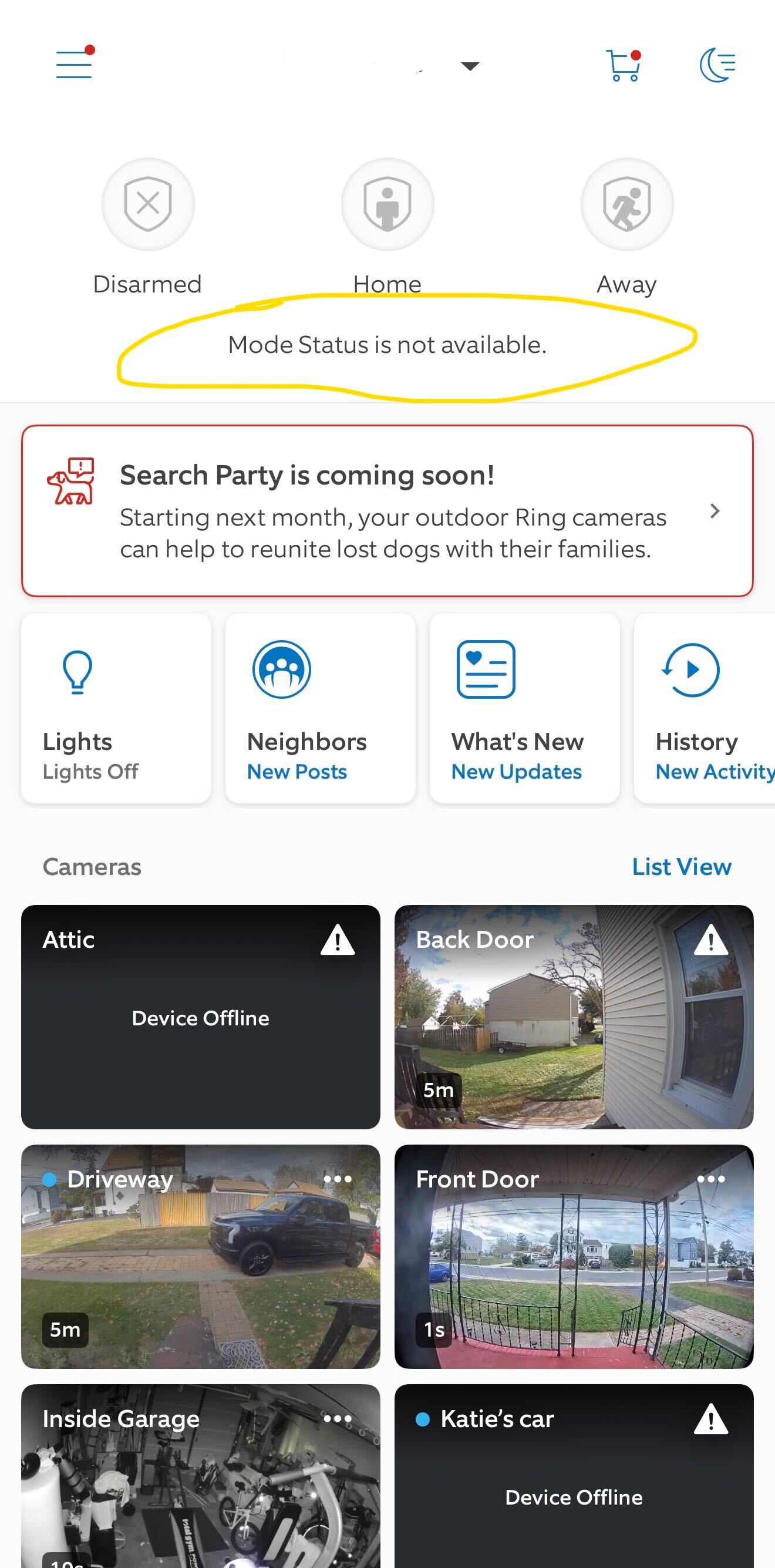
Ring, an Amazon-owned home security subsidiary, has been affected by the AWS outage all day.
My colleague, John Velasco, shared this image from his Ring system showing the modes aren't available. He reported that notifications are heavily delayed and that if you subscribe to the home security service the option to change modes is unavailable.
So if you had it turned off, you can't turn if back on through the app.
Outage affecting small businesses

A reader, Rob W., reached out us to note that the AWS outage is affecting small businesses that rely on services that utilize AWS. His examples included Shopify (which hosts stores), Finale Inventory (ecommerce software), and Shipstation (shipping management).
Rob said that he hasn't been able to access his Shipstation account at all today with other issues affecting the other services.
"This AWS outage is very much hurting small businesses too," he said.
As mentioned, there are a ton of services and sites that use AWS as a major part of their infrastructure. Even with the fixes, it may not be enough to recover the day for some businesses.
Managing tickets via Ticketmaster may not be working
pic.twitter.com/YU9B0TGawOOctober 20, 2025
If you're attempting to attend a live event tonight and had to purchase tickets through Ticketmaster, you may not be able to access them.
As noted by the Toronto Blue Jays hosting the Seattle Mariners in the MLB playoffs tonight, the issue means that people can't manage their tickets for the game.
As of this writing, no solution has been presented for potentially affected fans.
Latest update from AWS
AWS provided another update on its Service health page saying that "service recovery across all AWS services continues to improve."
That does appear to be the case based on Down Detector. We're seeing a number of services that were impacted with declining reports. The AWS page has steadily gone down from a high of nearly 10,000 reports to around 6,500 as of this writing.
That doesn't mean we're out of the weeds. It's clear that things aren't quickly turning back on and some services may still be experiencing ongoing outages.
Platforms coming back online

While a number of platforms, apps and websites have been affected by the ongoing AWS outage we've specifically focused on Venmo and Snapchat which seemed to see more reports than others.
We can see that things are starting to settle down as both of significantly declined in reports since earlier highs.
At one point, Snapchat hit 22,000 reports on Down Detector before dropping precipitously before holding around 7,000 for several hours. As of this writing, that number finally dipped under 2,000.
Venmo, which peaked around 8,300 reports around 8:30 am Pacific, has dipped all the way under 700 on Down Detector.
This isn't to say that every service has recovered equally. I'm currently seeing sites like Fetch, Ancestry.com and Fan Duel spiking but I am currently unaware if those services use AWS or are seeing a delayed impact.
How the AWS outage happened
As we've seen today, AWS is a lynchpin of the internet, concerningly so.
With that in mind, my colleague Amanda Caswell, took a look at how the outage happened, why it may have occurred and why it broke the internet. If you want to know more, I suggest you give it a read.
Looking up from AWS

The AWS Service Health page received another update and things looked to be on their way to repaired.
The severity has been reduced from "degraded" to "impacted" though that impact is still hitting 82 AWS services.
From what I can see, AWS is starting to open things back up a bit as they "continue to make progress toward pre-event levels."
Reports over on DD have finally gone under 5,000 for the first time since things started spike around 6 am Pacific.
Let us know, are things back up for you?

With service seemingly back on track from AWS, let us know if you're starting to see apps and websites working again.
For example, do you use Snapchat or Venmo? Can you use them. Or do you have Ring and can update your cameras again?
You can email me at scott.younker@futurenet.com.
You reported in, and things are still down

A little bit ago I asked if people were seeing things come back online and received several emails from readers that basically saying, "Nope."
Here's a little roundup of services that readers are saying they can't access or isn't working properly:
- Ally Bank
- Amazon Firestick
- Amazon Pharmacy
- Autodeck Creative Cloud inckuding Revit
- Canvas by Instructure
- EA
- Epic Games
- Physical ATM in Kansas
- ShipStation
- Sling
- Steam
- Toast
- xtraChef
The affected region covers the east coast and some of the midwest of the United States and that's where reports appear to be coming from.
Again, it's a reminder of how many services utilize AWS and how widespread this outage actually is.
We appreciate readers reaching out and letting us know how this ongoing outage is affecting them.
Where we stand after more than 12 hours
If you haven't been following along since the start we've been covering the AWS outage since 1 am Pacific/4 am Eastern/9 am UK.
Like the Crowdstrike outage from 2024, today's AWS problems were massive and affected multiple services across the country, though not as global.
Things haven't completely settled back to normal with though reports have been in a steady decline since 11 am PT. On Down Detector, reports are hovering around 3,500, a nice drop from our 2:30 pm check-in when it was at 5,000. Though that may be going up again.
AWS just posted an updated reporting that its restored "EC2 instance launch throttles to pre-event levels" and the launch failures have recovered everywhere.
The company does note that there is a backlog of analystics and reports that need processing.
As seen by our previous post, despite declines on Down Detector and encouraging updates from AWS, things aren't fully back yet and it may be a minute before we get there.
Fan Duel down?

The sports betting service Fan Duel seems to be down. A few readers reached out saying they couldn't login.
Fan Duel appears to use AWS and I'm seeing it spike on Down Detector.
AWS calls it
I'm still seeing a lot of reports on Down Detector and a few readers are saying they still can't access some apps, but more are writing in to say that their services are back up.
On the AWS Service Health page, the issue is now resolved as resolved.
Here's the full summary from AWS:
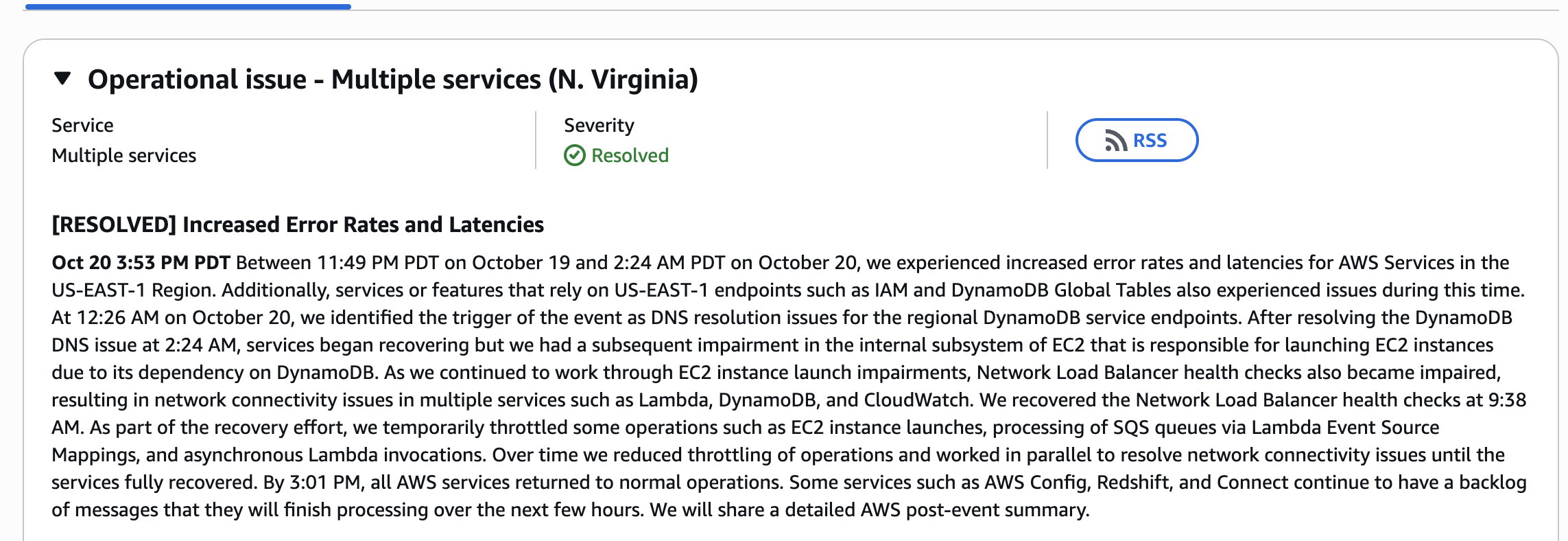
Between 11:49 PM PDT on October 19 and 2:24 AM PDT on October 20, we experienced increased error rates and latencies for AWS Services in the US-EAST-1 Region. Additionally, services or features that rely on US-EAST-1 endpoints such as IAM and DynamoDB Global Tables also experienced issues during this time. At 12:26 AM on October 20, we identified the trigger of the event as DNS resolution issues for the regional DynamoDB service endpoints. After resolving the DynamoDB DNS issue at 2:24 AM, services began recovering but we had a subsequent impairment in the internal subsystem of EC2 that is responsible for launching EC2 instances due to its dependency on DynamoDB. As we continued to work through EC2 instance launch impairments, Network Load Balancer health checks also became impaired, resulting in network connectivity issues in multiple services such as Lambda, DynamoDB, and CloudWatch. We recovered the Network Load Balancer health checks at 9:38 AM. As part of the recovery effort, we temporarily throttled some operations such as EC2 instance launches, processing of SQS queues via Lambda Event Source Mappings, and asynchronous Lambda invocations. Over time we reduced throttling of operations and worked in parallel to resolve network connectivity issues until the services fully recovered. By 3:01 PM, all AWS services returned to normal operations. Some services such as AWS Config, Redshift, and Connect continue to have a backlog of messages that they will finish processing over the next few hours. We will share a detailed AWS post-event summary.
The team behind AWS previously said that it would take some time to cycle through the backlog and data which may be why some services aren't totally back up yet.
As an example, Fan Duel was spiking but I'm already seeing those reports start to go down.
The $2.5 billion question
Our Managing Editor, Computing, Jason England, asked an important question this morning: How many more AWS outages until the internet builds a real backup plan?
We mentioned it several times during the course of this live blog that the internet is heavily reliant on AWS, perhaps a little too much. The billions of dollars lost during the outage should be a message to everyone, but we'll see if the internet actually takes notice.
And to top it off, we're seeing another small spike in Down Detector reports for AWS today. Could we be in for another day of AWS issues?
Over 1,000 reports again
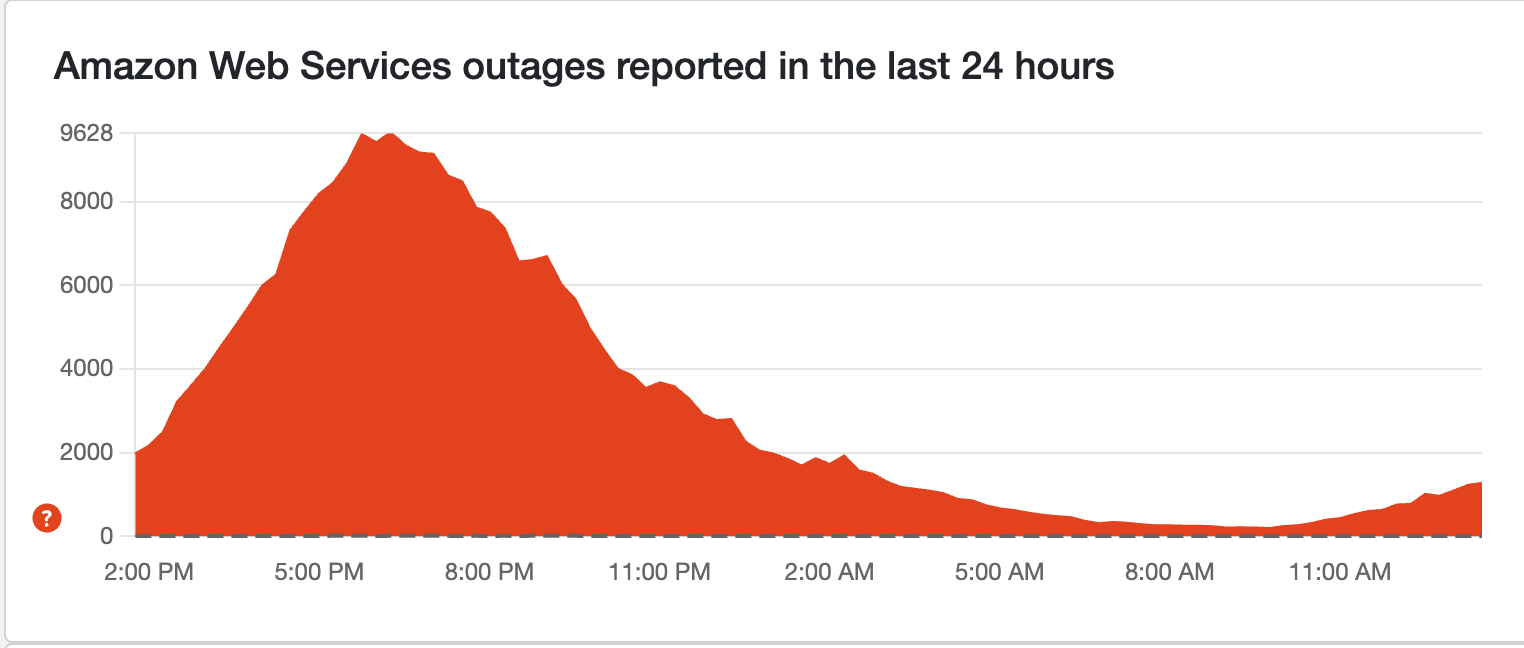
So AWS went down yesterday due to a DNS issue that cascaded to services across the planet. This was supposedly fixed yesterday, but reports have started creeping up again on Down Detector this morning.
And you'll never guess who the culprit is...yep, it's US-EAST-1 again. I've already written about this being a key problem in having a lot of the internet reliant on one server region.
Could this be trolls hitting Down Detector to get the internet riled up or something more serious? We'll keep you posted.
Other services reporting issues
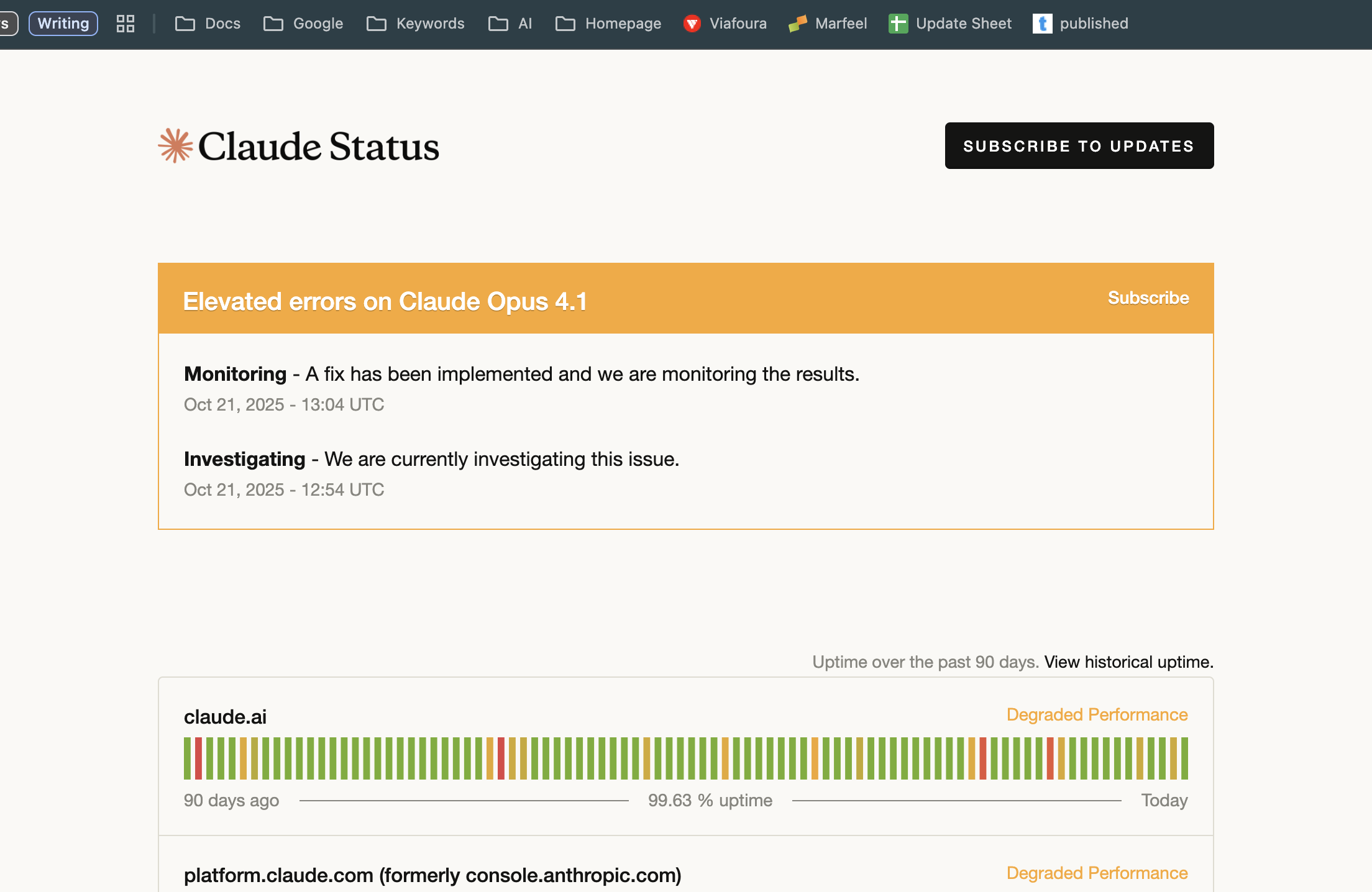
As we know, when AWS goes down, a lot of the internet goes down with it. So it's no surprise to see Anthropic's status page showing a Claude outage. Will more services start to go down? It depends on whether AWS is just experiencing a blip or a second round of the massive outage is underway.
Cloudflare showing warning signs

Currently, we're seeing network issues in Frankfurt. In case you're not aware, Cloudflare is often used with AWS, which could be another sign that things aren't all good in the Amazon Web Services space, but we'll have to wait and see.
You can read more on what's happening with Cloudflare on the status page, but it's worrisome to say the least.
Staying steady
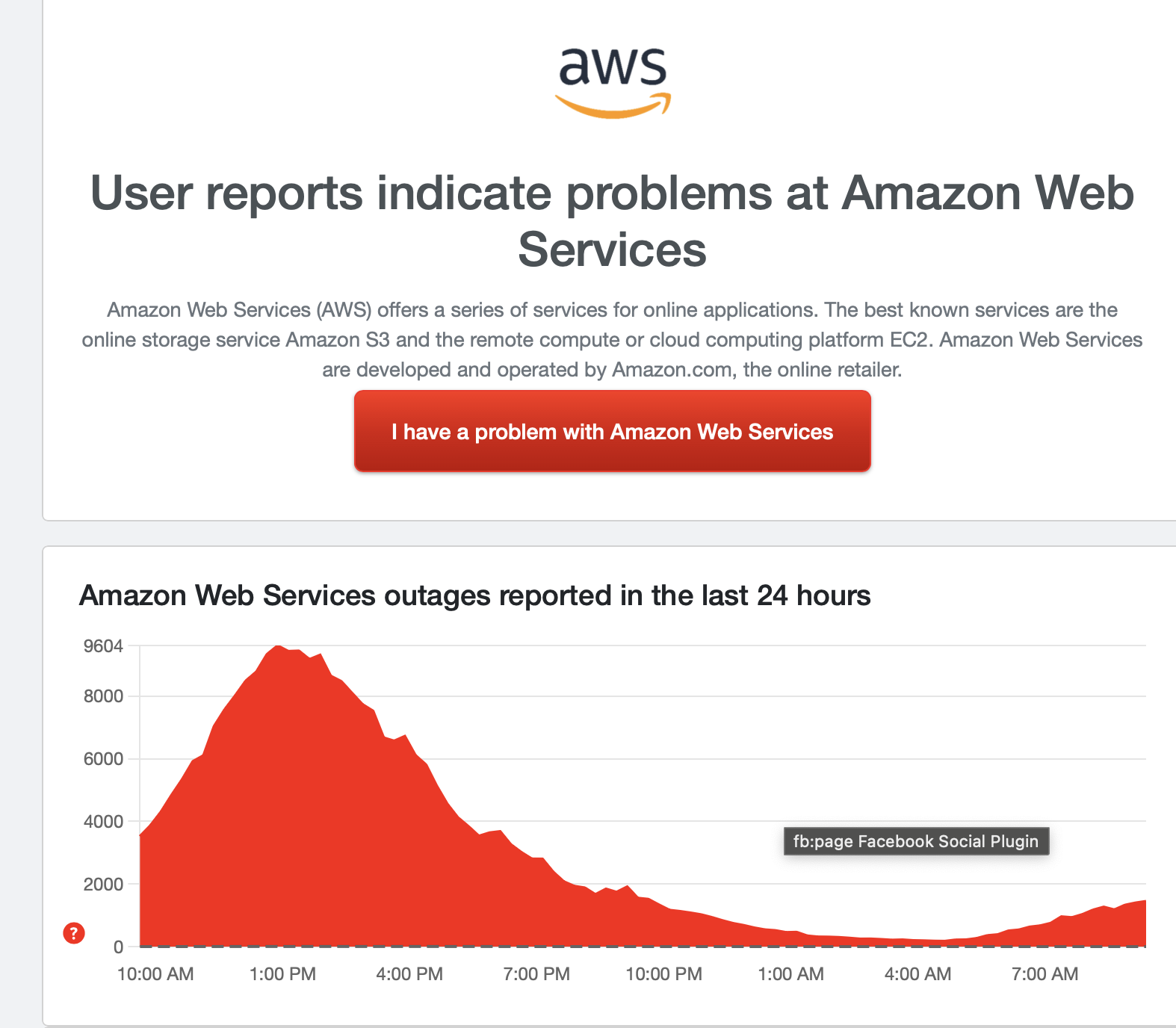
AWS reports are remaining mostly steady on Down Detector. It's still a high number of reports, 1,447 as of this post, but it's nothing like yesterday when we saw reports rise into the ten thousands range. We'll continue to monitor the situation to see if it gets worse, but for now it seems we're stuck somewhere between a full outage and a small bug.
Is it just updates?
This could just be fixes being applied on the fly by AWS, but not expecting this to be as hugely widespread as yesterday. We'll keep an eye on it
AWS status is okay
On the AWS status page, everything looks to be in working order. The last update it from yesterday when the hosting giant said everything was resolved, so it's still not quite clear why we're seeing this sudden rise in reports this morning.
1,000 range
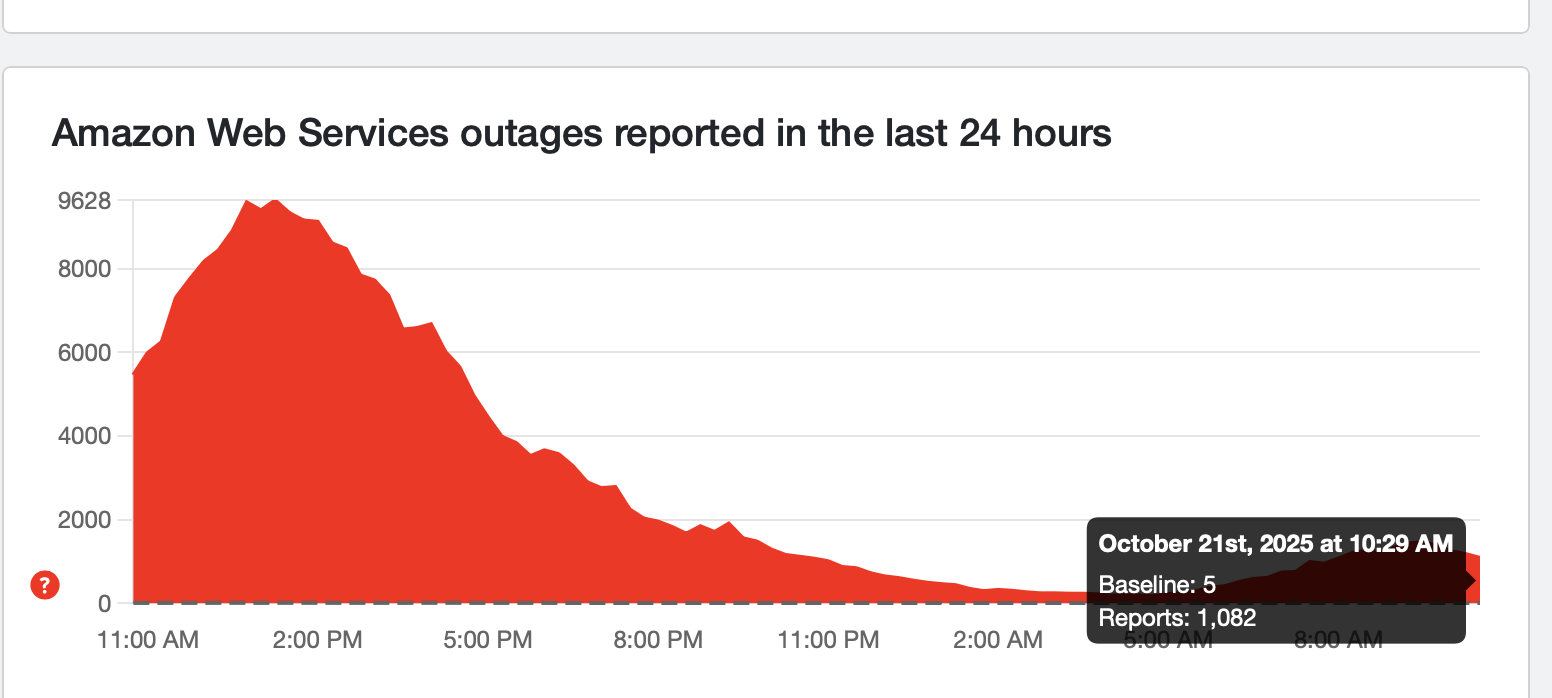
We've officially made it into the 1,000 range, which is close to where it hovered overnight due to straggling reports coming in. It's not quite low enough where we'd call anything resolved yet, but it's getting there.
Those NFTs are...
NFTs are amazing because you apparently “own” them but the AWS outtage yesterday took out everyones apes lol
— @junlper.beer (@junlper.beer.bsky.social) 2025-10-21T15:09:31.565Z
Someone on Bluesky noticed that popular NFTs seem to have been taken offline by the issues with AWS. It's odd to see images that people "own" going down.
Under 1,000 now
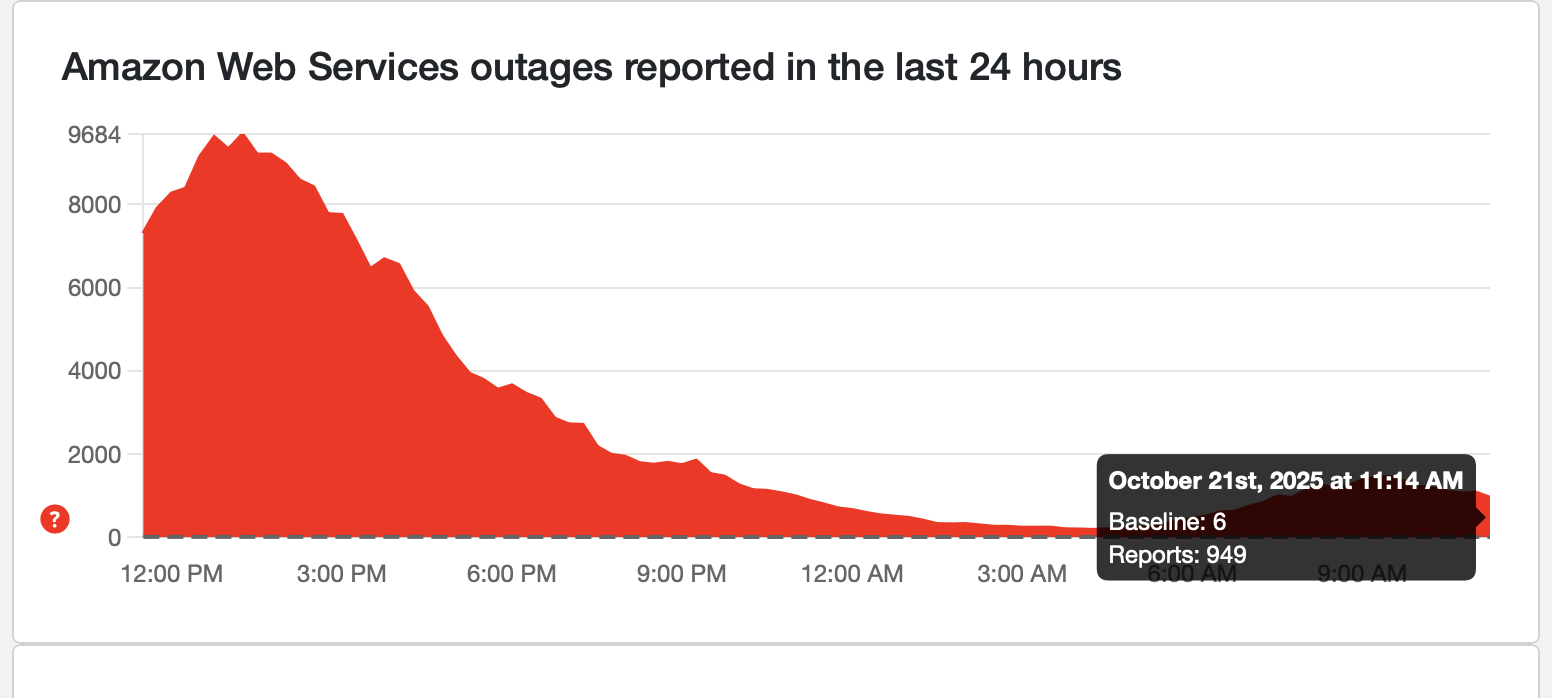
We've officially dropped below 1,000 reports, with Down Detector sitting at about 950 as of this post.
It seems okay... for now
Based on the reports slowly dropping, I think AWS is okay, at least for now. If, for some reason, you're still experiencing issues, make sure to head to Down Detector to report it
.png?w=600)