
Since Gemini 3 made its debut, it has successfully held the top spot on the LMArena leaderboard. This leaderboard is a crowdsourced ranking where thousands of real users compare AI models head-to-head across a wide range of tasks, voting on which response is better. But when it comes to reaching the toughest reasoning benchmarks, there's a new kid on the block, and it's already pulled ahead of Google — and it did it without training its own model.
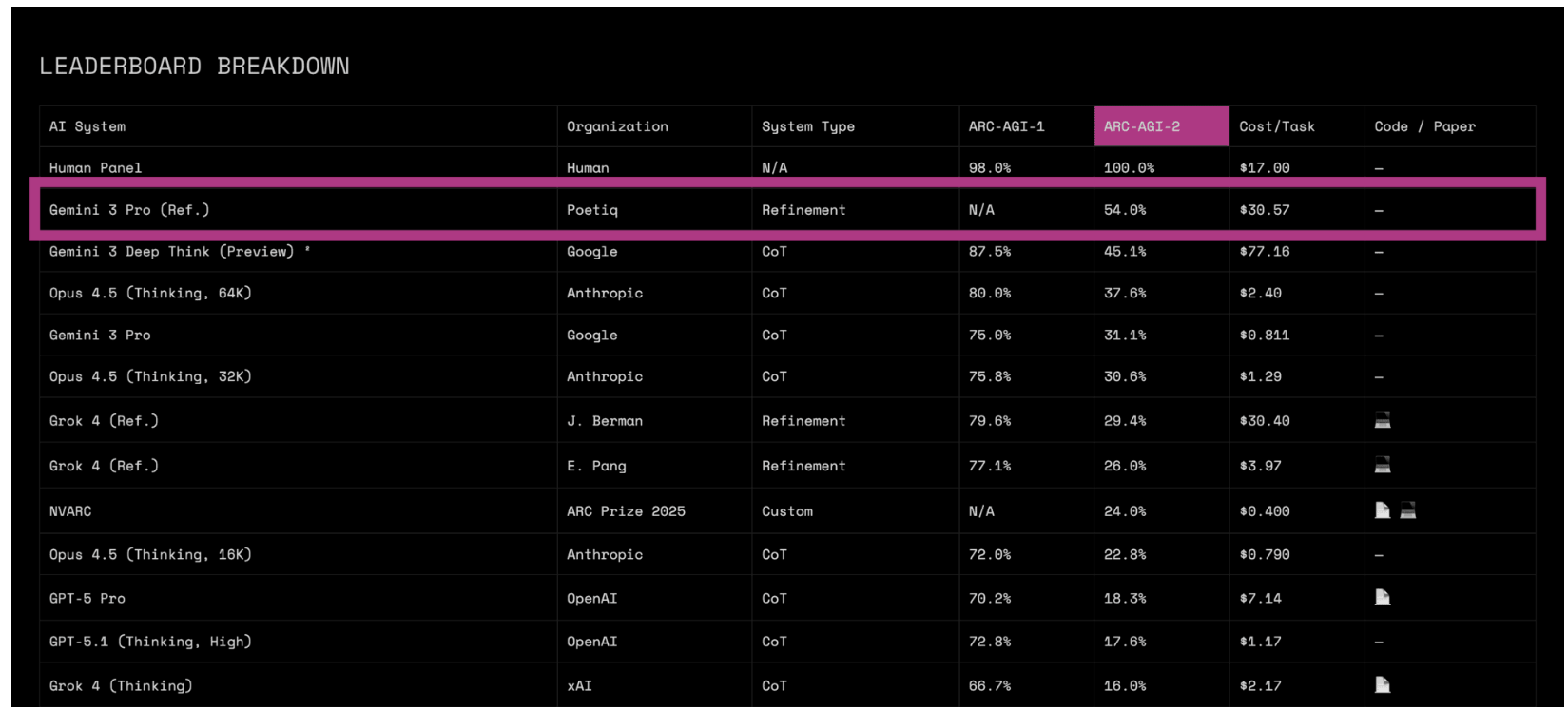
A six-person team startup known as Poetiq says it has taken the top spot on the ARC-AGI-2 semi-private test set, a notoriously difficult reasoning challenge created by AI researcher François Chollet. The startup’s system scored 54 percent, edging out what Google previously reported for Gemini 3 Deep Think at around 45 percent.
To put that in perspective, most AI models were stuck under 5 percent on this benchmark just six months ago. Cracking 50 percent is something researchers widely assumed was years away.
And the most surprising part: Poetiq’s breakthrough wasn’t powered by a new frontier model — but by a smarter way of orchestrating existing ones.
How Poetiq pulled this off
Instead of building a massive transformer from scratch, Poetiq developed what it calls a meta-system; essentially an AI controller that supervises, critiques and improves the outputs of whatever model you plug into it. For their ARC-AGI-2 work, the team used Gemini 3 Pro as the base model.
Poetiq describes the system as a tight optimization loop: generate > critique > refine > verify.
Here’s what makes it stand out:
- No retraining required: The system adapts to new models within hours
- Built entirely on off-the-shelf LLMs: No custom fine-tuning
- Lower cost: Google’s Deep Think reportedly costs ~$77 per task; Poetiq’s system ran closer to $30
- Open source: The solver is public and inspectable
- Self-auditing: The system evaluates its own answers before returning a final result
On the company website, Poetiq’s team says the approach works by squeezing more reasoning power out of existing LLMs — not by scaling brute-force compute.
Why ARC-AGI-2 matters

While most benchmarks measure narrow skills like coding or math, ARC-AGI-2 is designed to test something deeper: pattern recognition, analogy, abstract reasoning, and the kind of generalization humans learn in early childhood.
It’s intentionally hard and famously unfriendly to today’s LLMs. Even many frontier models fail spectacularly.
That’s why the leap from single-digit scores to 54 percent in half a year has turned heads. It suggests progress in reasoning methods, not just raw model scale.
However, Poetiq’s result applies specifically to the semi-private test set, which is not fully open to the public. The company site says the result has been verified by the benchmark’s organizers — but independent third-party replication is still pending, which is important for a benchmark this influential.
Perhaps the next breakthrough won’t come from bigger models as Poetiq’s work highlights a growing trend in AI: progress doesn’t always require billion-dollar infrastructure or a huge research lab.
If systems like this generalize beyond benchmarks, to planning, coding, research or real-world decision-making, it could reshape how AI is developed. Instead of waiting for the next breakthrough model, companies might build layered intelligence that makes today’s models smarter, cheaper and more consistent.
Bottom line
Poetiq has open-sourced its ARC-AGI solver so researchers can test, extend or challenge the results. The benchmark has a hidden test set, and history shows results can shift once more people run independent evaluations.
If Poetiq’s numbers hold, this could mark a turning point in AI reasoning research. A six-person team may have just shown that orchestrating models can rival, or even beat, training bigger ones. Poetiq just proved you don’t need a giant lab to win a round.
More from Tom's Guide
- I compared the privacy of ChatGPT, Gemini, Claude and Perplexity — here’s the one you should trust most with your personal info
- Elon Musk’s Grok 4.1 vs Anthropic’s Claude 4.5 Sonnet — here’s the AI model that’s actually smarter
- I tried ChatGPT’s Voice-to-Text feature — and it’s miles ahead of Otter and Google Recorder
Follow Tom's Guide on Google News and add us as a preferred source to get our up-to-date news, analysis, and reviews in your feeds.








