MemVerge, a provider of software designed to accelerate and optimize data-intensive applications, has partnered with Micron to boost the performance of LLMs using Compute Express Link (CXL) technology.
The company's Memory Machine software uses CXL to reduce idle time in GPUs caused by memory loading.
The technology was demonstrated at Micron’s booth at Nvidia GTC 2024 and Charles Fan, CEO and Co-founder of MemVerge said, “Scaling LLM performance cost-effectively means keeping the GPUs fed with data. Our demo at GTC demonstrates that pools of tiered memory not only drive performance higher but also maximize the utilization of precious GPU resources.”
Impressive results
The demo utilized a high-throughput FlexGen generation engine and an OPT-66B large language model. This was performed on a Supermicro Petascale Server, equipped with an AMD Genoa CPU, Nvidia A10 GPU, Micron DDR5-4800 DIMMs, CZ120 CXL memory modules, and MemVerge Memory Machine X intelligent tiering software.
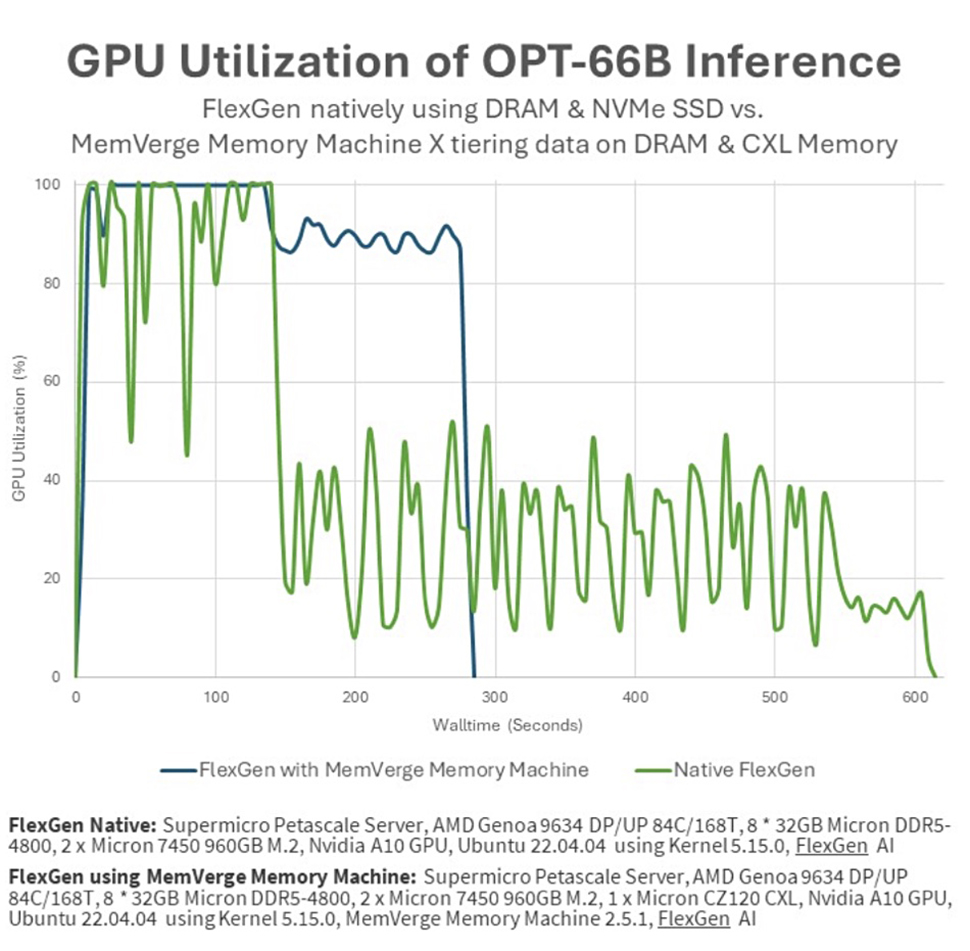
The demo contrasted the performance of a job running on an A10 GPU with 24GB of GDDR6 memory, and data fed from 8x 32GB Micron DRAM, against the same job running on the Supermicro server fitted with Micron CZ120 CXL 24GB memory expander and the MemVerge software.
The FlexGen benchmark, using tiered memory, completed tasks in under half the time of traditional NVMe storage methods. Additionally, GPU utilization jumped from 51.8% to 91.8%, reportedly as a result of MemVerge Memory Machine X software's transparent data tiering across GPU, CPU, and CXL memory.
Raj Narasimhan, senior vice president and general manager of Micron’s Compute and Networking Business Unit, said “Through our collaboration with MemVerge, Micron is able to demonstrate the substantial benefits of CXL memory modules to improve effective GPU throughput for AI applications resulting in faster time to insights for customers. Micron’s innovations across the memory portfolio provide compute with the necessary memory capacity and bandwidth to scale AI use cases from cloud to the edge.”
However, experts remain skeptical about the claims. Blocks and Files pointed out that the Nvidia A10 GPU uses GDDR6 memory, which is not HBM. A MemVerge spokesperson responded to this point, and others that the site raised, stating, “Our solution does have the same effect on the other GPUs with HBM. Between Flexgen’s memory offloading capabilities and Memory Machine X’s memory tiering capabilities, the solution is managing the entire memory hierarchy that includes GPU, CPU and CXL memory modules.”