To address concerns about power consumption of systems used for AI inference, hyperscale cloud service provider (CSP) Cloudflare is testing various AI accelerators that are not AI GPUs from AMD or Nvidia, reports the Wall Street Journal. Recently, the company began to test drive Positron AI's Atlas solution that promises to beat Nvidia's H200 at just 33% of its power consumption.
Positron is a U.S.-based company founded in 2023 that develops AI accelerators focused exclusively on inference. Unlike general-purpose GPUs that are designed for AI training, AI inference, technical computing, and a wide range of other workloads, Positron's hardware is built from scratch to perform inference tasks efficiently and with minimal power consumption. Position AI's first-generation solution for large-scale transformer models is called Atlas. It packs eight Archer accelerators and is designed to beat Nvidia's Hopper-based systems while consuming a fraction of power.
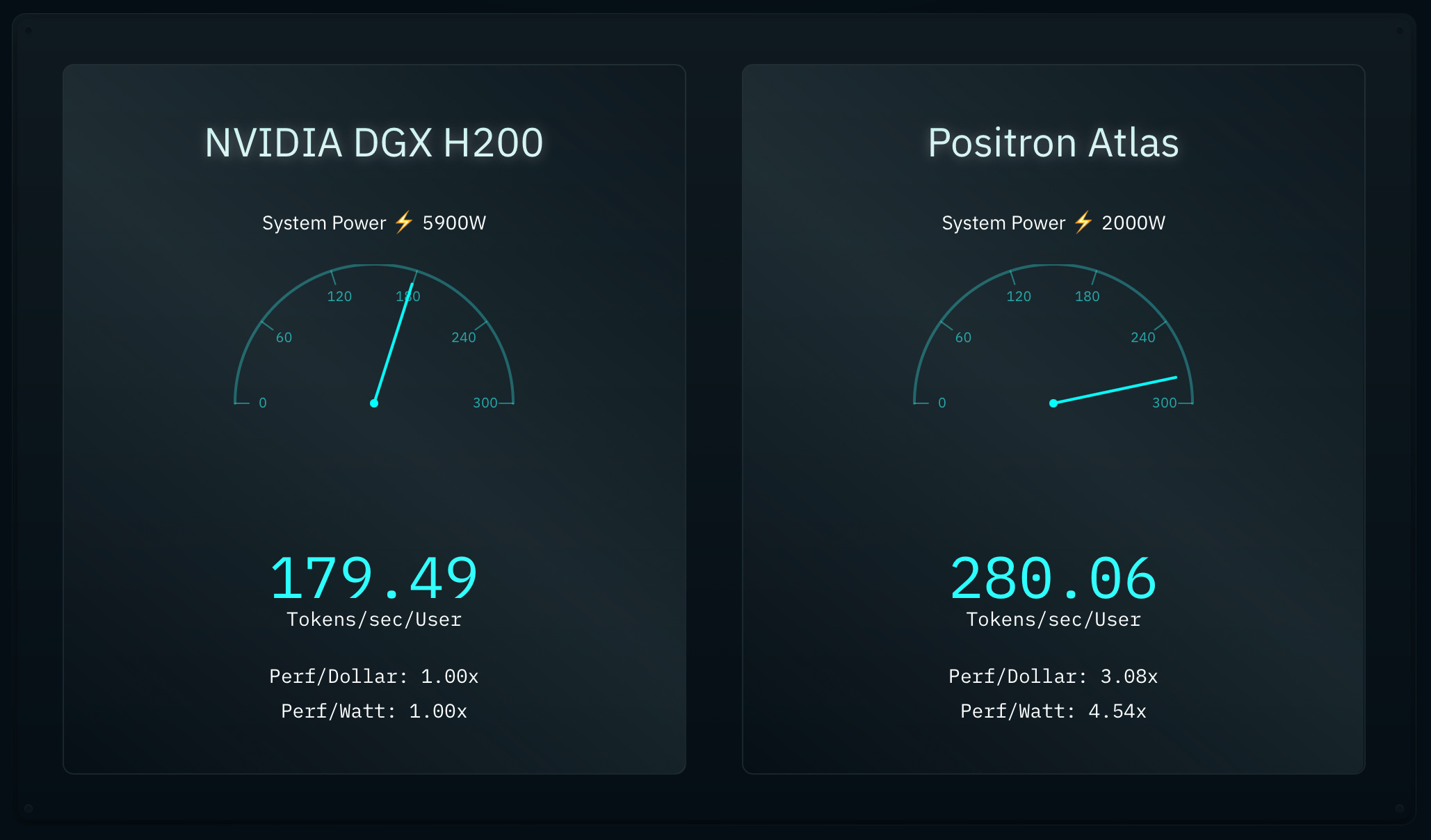
Positron AI's Atlas can reportedly deliver around 280 tokens per second per user in Llama 3.1 8B with BF16 compute at 2000W, whereas an 8-way Nvidia DGX H200 server can only achieve around 180 tokens per second per user in the same scenario, while using a whopping 5900W of power, according to a comparison conducted by Positron AI itself. This would make the Atlas three times more efficient in terms of performance-per-watt and in terms of performance-per-dollar compared to Nvidia's DGX H200 system. This claim, of course, requires verification by a third party.
It is noteworthy that Positron AI makes its ASIC hardware at TSMC's Fab 21 in Arizona (i.e., using an N4 or N5 process technology), and the cards are also assembled in the U.S., which makes them an almost entirely American product. Still, since the ASIC is mated with 32GB of HBM memory, it uses an advanced packaging technology and, therefore, is likely assembled in Taiwan.
Positron AI's Atlas systems and Archer AI accelerators are compatible with widely used AI tools like Hugging Face and serve inference requests through an OpenAI API-compatible endpoint, enabling users to adopt them without major changes to their workflows.
Positron has raised over $75 million in total funding, including a recent $51.6 million round led by investors such as Valor Equity Partners, Atreides Management, and DFJ Growth. The company is also working on its 2nd Generation AI inference accelerator dubbed Asimov, an 8-way Titan machine that is expected in 2026 to compete against inference systems based on Nvidia's Vera Rubin platforms.

Positron AI's Asimov AI accelerator will come with 2 TB of memory per ASIC, and, based on an image published by the company, will cease to use HBM, but will use another type of memory. The ASIC will also feature a 16 Tb/s external network bandwidth for more efficient operations in rack-scale systems. The Titan — based on eight Asimov AI accelerators with 16 GB of memory in total — is expected to be able to run models with up to 16 trillion parameters on a single machine, significantly expanding the context limits for large-scale generative AI applications. The system also supports simultaneous execution of multiple models, eliminating the one-model-per-GPU constraint, according to Positron AI.
The AI industry's accelerating power demands are raising alarms as some massive clusters used for AI model training consume the same amount of power as cities. The situation is only getting worse as AI models are getting bigger and usage of AI is increasing, which means that the power consumption of AI data centers used for inference is also increasing at a rapid pace. Cloudflare is among the early adopters currently testing hardware from Positron AI. By contrast, companies like Google, Meta, and Microsoft are developing their own inference accelerators to keep their power consumption in check.
Follow Tom's Hardware on Google News to get our up-to-date news, analysis, and reviews in your feeds. Make sure to click the Follow button.