
Written in collaboration with Reah Miyara, Head of Product at Arize AI
AI has a well-documented but poorly understood transparency problem. 51% of business executives report that AI transparency and ethics are important for their business, and not surprisingly, 41% of senior executives state that they have suspended the deployment of an AI tool because of a potential ethical issue.
In order to fully understand why AI transparency is such a challenging issue, we first ought to reconcile with some common misconceptions and their realities within AI transparency to gain a better view of the problem and the best way to address transparency within the context of the current ML tools in the market.
Technical Complexities Perpetuate Black Box AI
One of the driving forces behind the development of DevOps tools and practices was detecting and eliminating bugs or defects in software applications that may result in unexpected disruptions or risks to users. The DevOps framework enables faster and enhanced delivery of software products, improved automation, more swift solutions to problems encountered, and greater visibility into the performance and output of the system.
In the same vein as DevOps, MLOps has emerged to address the operational needs of developing and maintaining ML systems, though the practice is still in its early stages. Unlike software development, many machine learning systems deployed into the world today suffer from a lack of transparency and understanding into the models’ inner workings. Part of this dilemma stems from the sheer technical complexity of AI systems. While it is possible to build machine learning models that are easily interpretable, simple decision trees being an example, such models aren’t always helpful to achieving complex tasks or objectives.
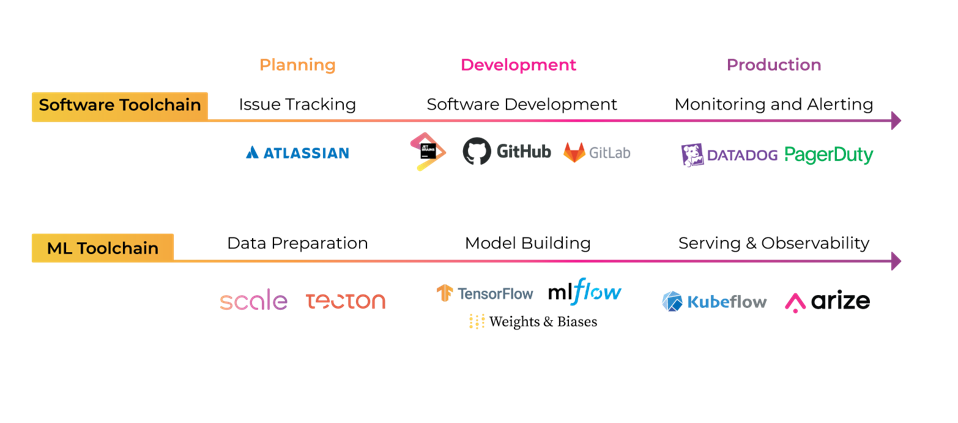
DevOps v. MLOps, Image by Author
To build machine learning models that can perform with high accuracy, the model must be fed with a high volume of quality data representative of the real-world data that the model will encounter once it is deployed. As thousands or sometimes millions of data points and hundreds of heterogeneous features are fed to the model to be analyzed, the complexity amplifies, making the system’s inner workings less comprehensible for even the people building the models.
The opacity of machine learning extends both to supervised and unsupervised models. In supervised models such as support vector machines, for instance, the opacity may result from high dimensionality, the number of transformations applied on data, non-linearity, and the use of complementary techniques such as principal component analysis.
Similar to support vector machines, random forests algorithms, commonly used in the finance industry for fraud detection and option pricing tasks, come at the cost of interpretability because they consist of a high number of decision trees and also go through a feature bagging process which makes it quite challenging to interpret. Unsupervised models such as k-means clustering also suffer from a lack of transparency. In k-means clustering, the clusters are defined based on parameters such as means, and it is difficult to determine which features were most important in producing the final output.
Misconceptions that make organizations hesitant to adopt more AI transparency
Misconception #1: If ML models are determined to behave in biased or unfair ways, we will automatically lose customer trust
Some organizations may worry that disclosure of the source code, the underlying mathematical model, the training data, or simply the inputs and outputs of a machine learning model may expose them to the risk of losing customer trust, dealing with intense public scrutiny, or disruptions to the deployment and use of their machine-learned innovations.
If an ML system is found to behave unfairly when it comes to gender, race, economic status, or any given group, this may not only lead to loss of trust with existing customers, but it may also subject an organization to public and regulatory scrutiny; potentially tarnishing their brand.
Another concern that organizations may have regarding transparency is that if faced with public backlash due to alleged bias or discrimination, they may have to halt the use of their ML systems or delay deployment, resulting in disruptions to their business operations. Amazon, for instance, had to halt the use of its ML-based hiring tool because the underlying model favored male applicants over female applicants for technical positions, resulting in heavy criticism that the organization was perpetuating gender disparity in tech.
Twitter has also recently faced public scrutiny due to its photo cropping function allegedly discriminating against black people and females because it gravitated towards white and male faces when cropping. Another criticism directed at Twitter was that the photo cropping algorithm focused on women’s chests and legs as salient features over their faces. Following the news reports and public backlash, Twitter investigated whether the allegations had merit, eventually publishing detailed technical reports about how the algorithms worked to shed more transparency into the issues. In a blog post addressing the investigation, Twitter also announced that it was tweaking the tool to eliminate the model biases found.
Reality #1: Adopting responsible AI practices helps establish trust with your customers and the general public
According to a recent survey by Capgemini, 62% of respondents said they would have higher trust in a company they perceived practiced ethical AI, 59% said that they would have higher loyalty to the company, and 55% said that they would purchase more products and provide high ratings and positive feedback on social media.
Consumers are increasingly more aware of the potential harms that AI systems may cause. They demand more transparency into the inner workings of such technologies that may have catastrophic effects on individuals’ lives, like denying them a loan, rejecting a job application, or quoting a higher health insurance price.
This is evidenced by another Study “Why addressing ethical questions in AI will benefit organizations”: Consumers are more aware of risks introduced by ML applications and they raise concerns over the opaque nature of AI: 75% of consumers stated that they demand more transparency from AI-powered tools. Furthermore, 36% of consumers expressed that companies must provide explanations on the inner workings of AI tools when ethical issues arise.
Considering the growing demand for more transparent AI, organizations can earn end users’ trust, bolster their customers’ loyalty and remedy the customers’ concern over the adverse effects of AI systems by bringing more transparency into their systems.
Misconception #2: AI transparency isn’t necessary because organizations can self-regulate
Another factor that plays into some organizations’ hesitancy in making ML systems transparent is that disclosure may reveal bias, discrimination, or unfairness embedded in the ML system, which can subject the organization to regulation or legal action.
For example, consider ProPublica's report on the COMPAS pretrial risk scoring program. ProPublica obtained personal data related to COMPAS scores and the criminal history of more than 18,000 individuals through a public access request and ran statistical analysis on the obtained data. The analysis revealed that the system was twice as likely to misidentify black individuals as high risk of re-offense compared to white individuals.
Various reputable news outlets brought the allegations by the report to public scrutiny, and the findings became a poster child on the issues of bias and discrimination in AI tools. As a result, the owner of the COMPAS software has faced legal action in court, though it was dismissed in the end.
If the data used to train the algorithm weren’t disclosed, it would have been next to impossible to prove the discriminatory effects of the program on black people.
Reality #2: AI transparency enables predictable and consistent regulation
As AI tools are deployed across many critical domains ranging from banking to employment to criminal justice systems, regulators are paying particular attention to the potential ill-effects of AI on fundamental rights and taking actions. AI transparency can streamline legal compliance efforts and preemptively shield your organization from possible legal action in the future.
In the Netherlands, for instance, a court ruled that the government cannot deploy the AI-based social security fraud detection system because of a lack of transparency into how the model calculated the risk of fraud, which violated individuals’ fundamental rights. Had the commercial vendor that sold the AI system designed for transparency at the start, the system’s use would likely not have been halted.
Another area where AI transparency can help with legal compliance relates to EU General Data Protection Regulation (GDPR). Article 14 of GDPR requires data controllers to provide meaningful information about the logic involved if they use automated decision-making systems such as AI models.
Imagine a scenario where a couple applies for the same loan amount, but they receive loans in different amounts. If the lender incorporated model explainability, they can determine which features had the highest impact on the output produced by the model and explain how the amount of loan is calculated for the individuals. This could help you comply with GDPR Article 14’s transparency requirements in a more timely manner.
Misconception #3: If protected class data isn’t used in model building, the model can’t be biased
Another source of concern for organizations when it comes to making AI systems transparent is the lack of access to protected data classes by their ML teams, making efforts to validate their model for bias or discrimination extremely difficult.
Bias can infiltrate a machine learning model during all project phases, from the initial formulation of the problem to model validation.
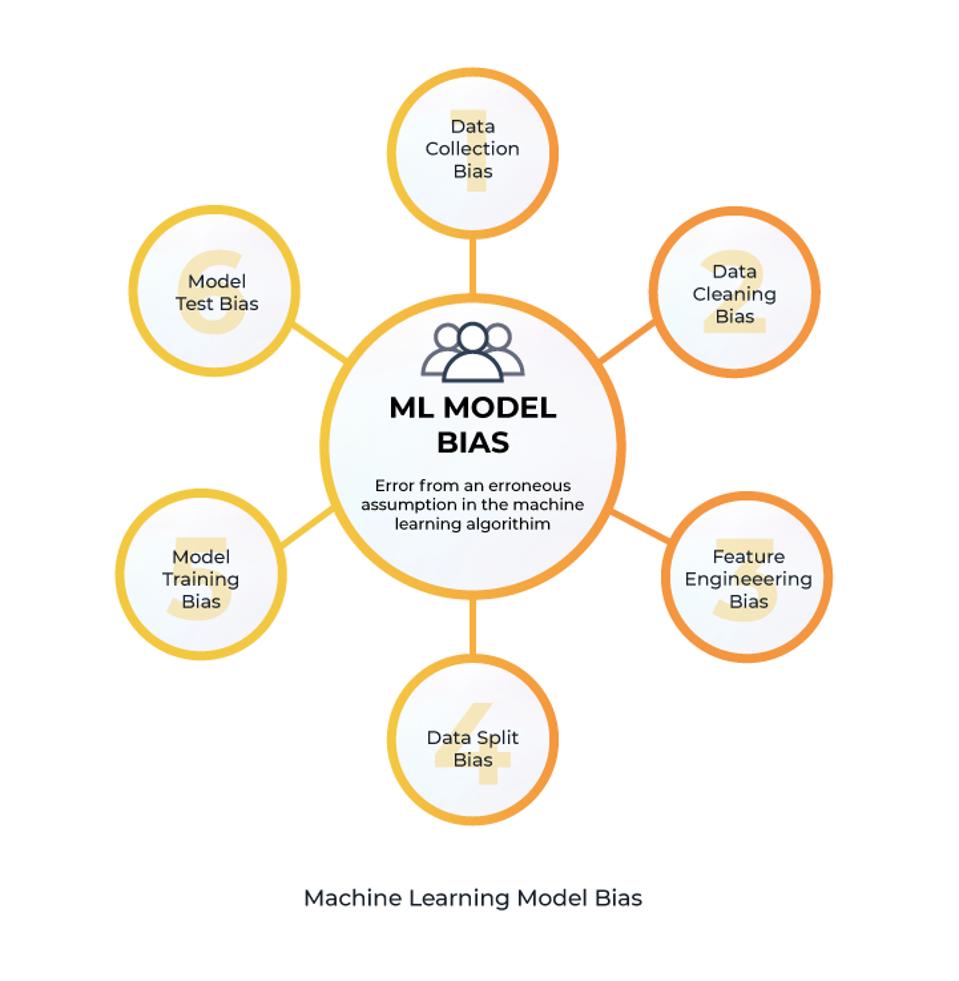
Types of Machine Learning Model Bias, Image by Author
In most cases, however, the bias will be related to specific data characteristics the model is trained on. Under- or over-representation of a particular group or category in the dataset, incomplete data, lack of heterogeneity of data sources, or historically inaccurate data are examples that may lead to bias in the machine learning model’s outputs.
Specific sensitive data such as gender, age, color, and marital status are considered protected under the Equal Credit Opportunity Act. Meaning lenders and underwriters, for example, are required to ensure that these categories of sensitive data are not used to determine the outcome of a loan application. Therefore, machine learning practitioners often don’t have access to this data to train or validate models to avoid injecting biases and retain plausible deniability.
However, this approach of omission doesn’t ensure a model’s outcome isn’t biased. Even without having access to sensitive attributes such as race or gender, models have been proven to pick up on other proxy attributes and exert proxy bias against certain groups. According to Barocas and Selbst’s Study, attributes such as ZIP Codes can function as proxies for sensitive attributes such as race and lead to discrimination and bias.
One well-known case of this phenomenon is the accusation against Facebook that it allowed discrimination against minority groups in its targeted ads services via the use of proxies for race. Even after Facebook removed the multicultural affinity category (race) for targeted ads, the advertisers could still use proxies such as ‘hip hop music’ or ‘black lives matter’ for race to target black people.
Reality #3: Access to protected class data can help ML practitioners understand where to root out biases
While perhaps counterintuitive at the surface, giving ML practitioners access to protected class data can help mitigate model biases.
By understanding which segments a model exhibits bias against, ML practitioners can take proactive steps to reduce or eliminate those biases by employing certain techniques. For example, in the preprocessing stage, techniques such as Counterfactual Fairness and path-specific counterfactual methods can be used to remedy inaccuracies in the data and to ensure that the sensitive attributes do not change the output.
With Counterfactual Fairness, the model is designed so that changes in sensitive attributes such as race, gender, or religion do not result in different outputs. For example, changing gender inputs from ‘male’ to ‘female’ to determine if the gender of the loan applicant had any impact on the outcome produced by the model.
Misconception #4: AI transparency leaves you vulnerable to losing intellectual property
There is a growing tension between the desire for AI transparency and an organizations’ interest in maintaining secrecy over their AI tools. Firstly, secrecy helps maintain their competitive advantage in the market. Another advantage is that it prevents malicious actors from gaming the AI tool and harming the business model or users.
Google’s PageRank, Amazon’s ML-powered recommendation system, and Instagram’s content recommendation algorithms are all examples of trade secrets.
Google, for instance, does not disclose the exact formula and list of all criteria, such as weight of backlinks or structure of a particular page’s source code, of how its ML-based search engine algorithm ranks web pages because this would enable ill-intent parties to rank higher on search results by gaming the system, potentially harming the user experience.
Alongside trade secrets, the companies also increasingly use intellectual property protection over their AI inventions, such as patenting their algorithms.
Many individual components of machine learning systems such as the algorithm, the models used, the source code, neural networks, and the datasets can all be protected as trade secrets. Some organizations fear that increased transparency brings the risk of disclosing intellectual property that they want to protect.
To further elaborate on this issue, let’s consider the following study, which demonstrated that it is possible to reconstruct a neural network using the saliency maps technique. Saliency maps are a technique used to explain the predictions of neural networks, particularly convolutional neural networks (CNN). Saliency maps help detect the parts of an input that had the highest impact on a particular layer in the network.
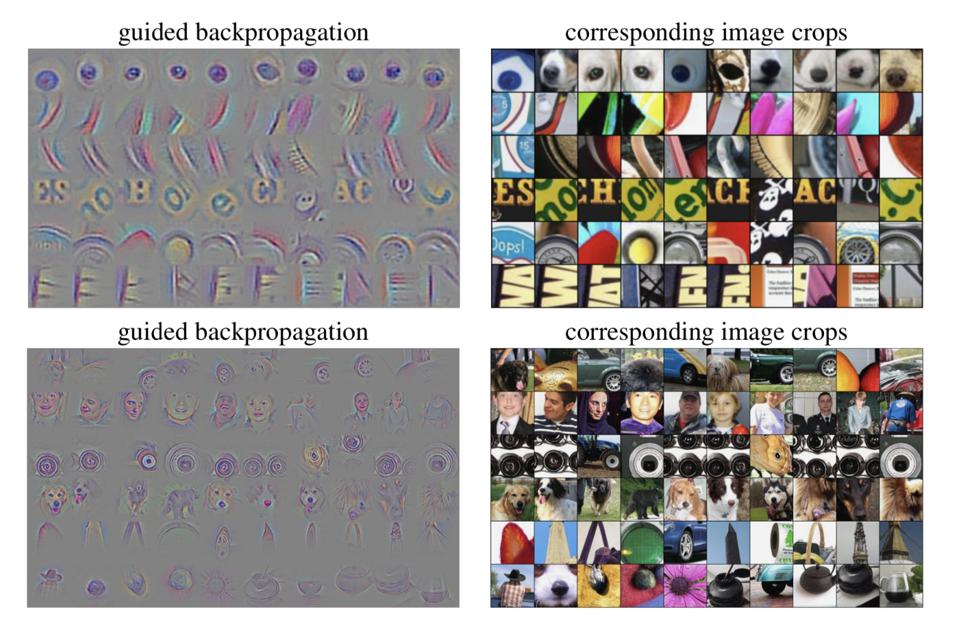
Saliency Map for its Respective Image Input, Image by [Springenberg et al. 2014]
In this study, researchers ran heuristic queries on input gradients. They managed to reconstruct the underlying model with few queries without any information on the data distribution and model class. In other words, the study revealed that providing an Explanation-API based on saliency maps was not only shedding light on certain predictions made by neural networks but it was also exposing the entire model.
Reality #4: Transparency doesn’t mean disclosing intellectual property
There’s a misconception that transparency renders trade secret protection over datasets, algorithms, or the models meaningless; this is a misunderstanding of the meaning and boundaries of transparency, along with trade secret protections afforded by law.
Opacity or transparency of an ML model is with respect to a particular agent or party, and an ML system can be considered to satisfy transparency when the relevant agent has the relevant knowledge to understand how the system works.
Let’s apply these criteria for transparency in respect to end users, who are most likely to be subject to adverse effects of ML systems. Given that most non-technical end-users will not be interested in the highly technical inner workings of an ML system, such as the type of model used or training method, this information is generally irrelevant to satisfy transparency for these users. In the case of a non-technical end-user, an acceptable level of transparency can be achieved by explaining what variables led to a particular output and possibly how the counterfactual output would be produced.
For example, imagine a university uses an ML-powered scoring tool that classifies applicants as ‘high potential’ and ‘low potential’; the tool rejects an applicant, and the applicant makes a request to learn what led to the decision. In deciding whether the university’s ML tool is transparent, it is necessary to contemplate whether the model is understandable to the relevant agent (the applicant, in this example).
In this scenario, the university can utilize methods such as SHAP or LIME to reveal what features had the highest impact on the classification made. By deploying this method, the university can explain to the student the reasoning behind the classification in an easily understandable format without disclosing the underlying source code, the entire dataset, or the algorithm.
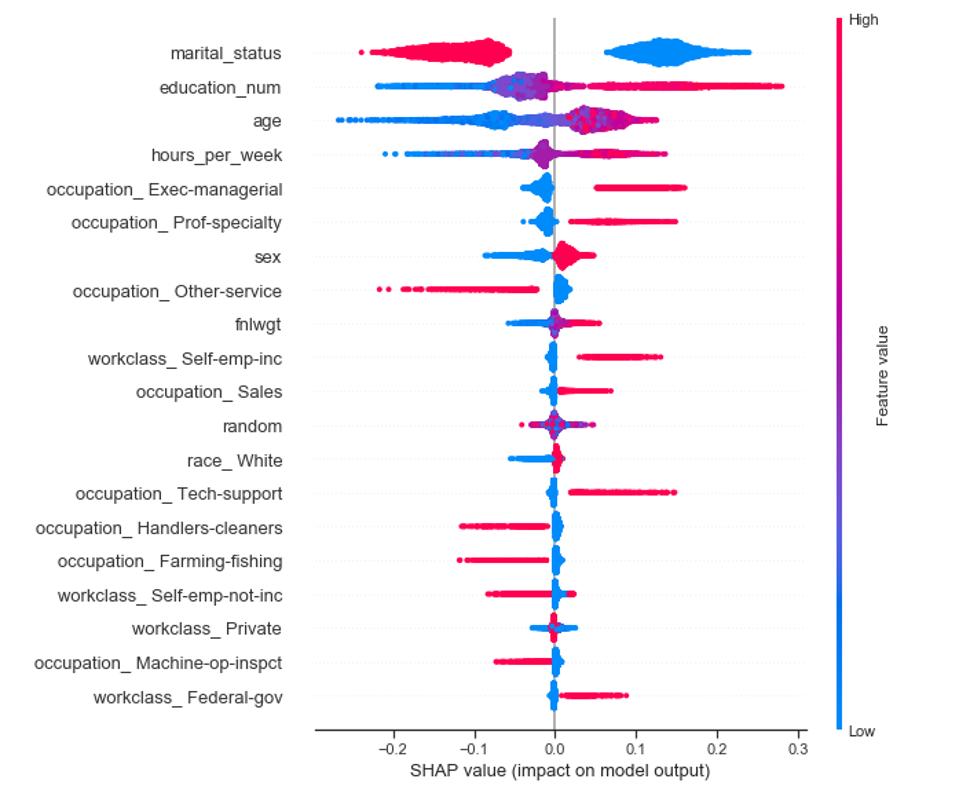
Example of SHAP values, Image by KD Nuggets
According to a recent study that analyzed 18 most prominent guidelines published on AI transparency since 2016, transparency can be fulfilled in a number of ways. Here’s a look at what criteria these guidelines set for algorithmic transparency:
– What kind of machine learning algorithm is used
– How the algorithm works
– How the algorithm was trained and tested
– What the most important variables are that influence the outcome.
While there isn’t a single definition and criteria on what transparency means and when it is satisfied, organizations should strive to create and disclose their definition and criteria to their customers and end-users.
Overcoming black box AI with ML observability tools
As we addressed in the previous section, transparency of an ML model is only with respect to a given agent, the relevant recipient of a piece of information on how an ML system works.
Making your ML system transparent to external parties such as your end-users, regulators, and even to the general public cannot be realized without having proper, purpose-built tools that give you contextual information about the quality of your data that your model is trained on, the changes in the model, values of attributes and how they change through time, and the root causes of problems you encounter.
Given the volume of data fed into ML models throughout its entire offline and online lifecycle and the dynamic nature of these systems, manual inspection of ML models is neither efficient nor effective for organizations operating at scale.
ML observability refers to the practice of obtaining a deep understanding of a model’s performance across all stages of the model development cycle. An ML observability platform can monitor and flag each change in the statistical properties of values, such as the data distribution, of each feature and send alerts in real-time for investigation.
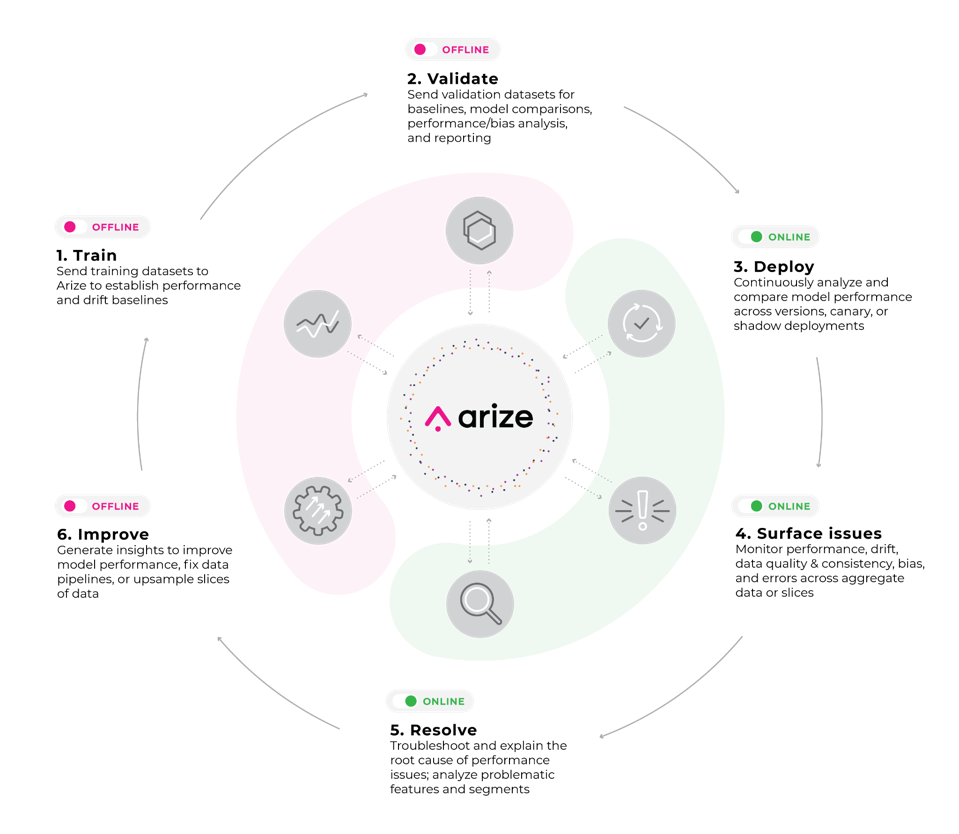
Machine Learning Observability Workflow, Image by Author
ML observability platforms differ from monitoring in the sense that it not only detects problems or sends alerts, but it enables you to uncover the ‘why’ behind any degradation or meaningful change in the model’s outputs. Capabilities such as explainability help model builders understand how their model weighs different feature inputs into its decisioning, performance slices let them home in on specific cohorts the model is underperforming, and comparisons to offline datasets and benchmarks expose areas for improvement.
Issues around transparency are unlikely to be resolved anytime soon so long as AI systems remain opaque. Considering that ML systems are increasingly deployed in areas such as criminal justice, the employment process, and banking, where vulnerable groups can be exposed to discrimination and bias, it is critical to ensure AI transparency so that AI tools are trusted by all stakeholders across the business, consumers, and government.
ML observability tools can help you transform black box models into ‘glass box’ models that are more comprehensible to human beings. Which ultimately enables organizations to build more transparent AI systems.







