Chances are you were hit by internet troubles yesterday. The AWS outage impacted over 2,500 companies and services worldwide — estimated to cost everyone involved roughly $2.5 billion.
And it was all because of one server region in Northern Virginia — a single point of failure took down thousands of companies and essential public services across the globe.
When AWS sneezes, half the internet catches the flu.
Monica Eaton, Founder and CEO of Chargebacks911 and Fi911
And that happened even though AWS best practice states that companies use server regions closest to the largest pool of end-users of your service. So how did this happen? And did it just expose how fragile the internet actually is? Spoiler alert: Yes. Let me explain.
How did the AWS outage happen?

Amazon has issued a statement about the outage, but it's a nothingburger that’s probably been posted for legal reasons. Our AI Editor Amanda Caswell has provided much more detailed insight into how the AWS outage happened.
But to summarize real quick, the crisis began inside Amazon Web Services' busiest data hub in Northern Virginia (US-EAST-1), where a core networking failure caused a problem with the Domain Name System (DNS). Think of the DNS as the internet’s central phone book, and DynamoDB (a critical database service) was its most important entry.
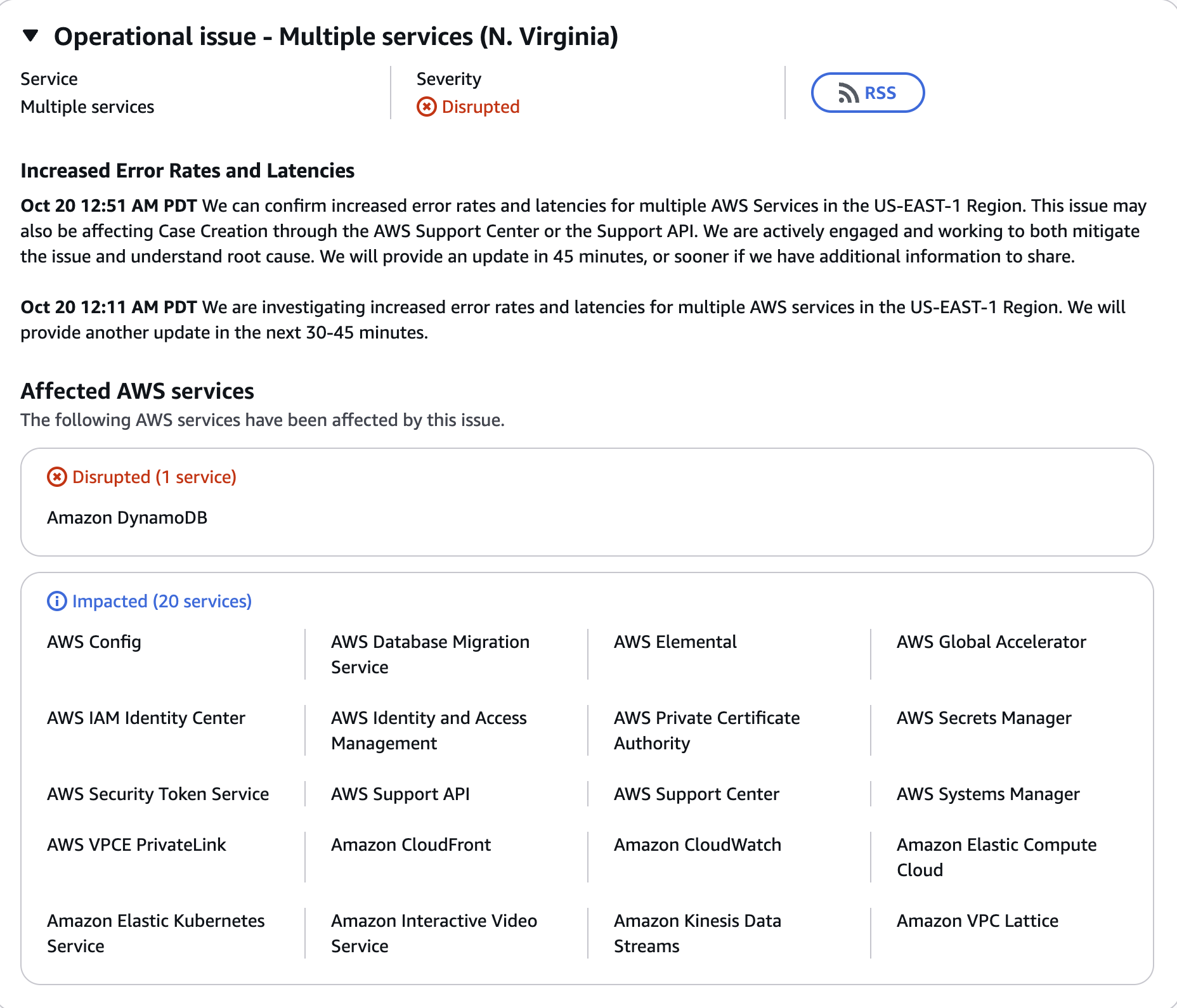
The metaphorical phone book started spontaneously deleting the address for the main warehouse. All the internal systems for key services were suddenly trying to call the DynamoDB database, but the DNS could not provide the correct digital address. With no instructions on where to send the data, all those applications stalled, timed out and started to crash.
This initial failure then triggered a massive cascading failure across the entire cloud. Imagine a power grid: when one major substation goes offline, the sudden surge of traffic overwhelms the remaining infrastructure. US-EAST-1 is that major substation that controls the flow of power across all other stations, which also holds that “phone book."
This caused services like EC2 (virtual computers) and Lambda (serverless code) to fail, creating massive backlogs of requests. Even after Amazon fixed the "phone book" entry, the grid was still overloaded, requiring hours of manual work and "rate limiting" (temporarily slowing down new traffic) to clear the congestion and fully restore stability.
It really highlighted the flaws of the way AWS works right now. "The real story isn't just that AWS had a critical-issue, but how many businesses discovered their platform partner had no plan for it, especially outside of US hours," Ismael Wrixen, CEO of ThriveCart commented.
"This is a harsh wake-up call about the critical need for multi-regional redundancy and intelligent architecture.
Who was affected?

Yes, we all lamented the big problems. Snapchat and Reddit went down, so did Fortnite, PlayStation Network, various streaming services and a whole lot of content-based sites. Duolingo and Wordle streaks were at risk, but there were more surprising victims given the location.
If you have smart home and personal security tech, chances are you couldn’t do a whole lot around your house. With Ring doorbells/cameras and Amazon Alexa devices being cloud-dependent using AWS, automations and routines collapsed instantly. For those who use Life360 for family peace of mind, that went down, too.

Education also took a hit, as the major educational platform Canvas went down — leaving students unable to access coursework or submit assignments. Financial tech also took a dive, as several major U.K. banks experienced outages, as well as Venmo and Coinbase in the U.S.
But most concerningly were critical public services, transport and enterprise systems. The U.K.’s tax authority HMRC went down, United Airlines and Delta’s websites were offline, which meant people couldn’t book flights, and Zoom, Slack and Xero were out. All because of one hub in West Virginia!?
The offside lines were drawn for the first time this season to rule out Thiago's second goal for Brentford ❌There is no Semi-Automated Offside Technology available today due to the AWS outage 👀 pic.twitter.com/7vxv6fZ3CEOctober 20, 2025
Also, hilariously, AWS outage issues were felt in the world of sports, as the semi-automated offside technology used in Premier League soccer went down — making VAR in the West Ham match a more involved process.
What needs to happen now?

Here’s the $2.5 billion question for Amazon Web Services — why on Earth is a lot of the world’s key infrastructure reliant on a single point of failure like this? Yes, I know it’s the “default” option, but that is based purely on the historical context. And historical context shouldn’t make a single region the central nervous system for daily website traffic.
The digital world relies on a handful of massive tech companies for critical services like this, so is it time for regulators and companies to mandate a change?
The big actions
First thing's first, more research is needed into cloud infrastructure, to avoid vulnerabilities turning into cascading catastrophes like this again in the future.
"Within hours, thousands of applications across finance, healthcare and government sectors experienced major interruptions — a textbook example of a cyber cascading failure,” Professor Ariel Pinto, chair of the Cybersecurity Department at UAlbany’s College of Emergency Preparedness, Homeland Security and Cybersecurity stated.
“As cloud services become increasingly central to global digital infrastructure, the need for sophisticated risk modeling becomes critical. Our digital world rests on complex interdependencies that demand rigorous scientific analysis.”
There’s also precedent for government action here, too, and these questions need to be asked over and over. If any political figures stumble upon this article, please take these questions and put them to Amazon! And if I may suggest two solutions:
- Make multi-region mandatory: The system architecture of key services is too critical to be based in just one place. There should be a live failover in a separate region, like Europe or Asia, to circumvent this in the future.
- Governments need to get tougher: Rules for critical services like banking, education, transportation and government services should have a backup plan baked into their IT. That means tougher requirements like multi-cloud strategies.
"Every business that relies on cloud infrastructure should have a clear strategy for resiliency.," Debanjan Saha, CEO of DataRobot and former AWS General Manager added.
"That means thinking beyond a single data center or region, and ideally beyond a single provider — building for multi-region, and where possible, multi-cloud or hybrid environments. This inevitably adds cost and complexity, but for any organization where uptime is mission-critical, that investment is well worth it."
What can you do?
But what about you? Because if history repeats itself, we could all go back into the status quo until the next time AWS coughs and most of the internet catches the flu.
Well, the first thing you can do is make your smart home outage-proof. Ring doorbells and Alexa devices are entirely cloud-dependent. You need to look for devices that run on local protocol systems like Matter, which makes local control a core requirement.
But the long game for you (and me, and everyone else) is to demand better redundancy from the tech you use every day. And the way companies listen is to hit them where it hurts — their wallets.
Follow Tom's Guide on Google News and add us as a preferred source to get our up-to-date news, analysis, and reviews in your feeds. Make sure to click the Follow button!

.png?w=600)