What you need to know
- A study by researchers from Stanford shows a decline in the performance of OpenAI's chatbot.
- The researchers used four key performance indicators to determine whether GPT-4 and GPT-3.5 were getting better or worse.
- Both LLMs display varied performance and behaviors in different categories.
At the beginning of this year, the doors of generative AI flung wide open, bringing forth a new reality of opportunities. Microsoft's new Bing and OpenAI's ChatGPT have been at the forefront, with other companies closely following suit with similar models and iterations.
While OpenAI has been busy pushing new updates and features to its AI-powered chatbot to enhance its user experience, a group of researchers from Stanford has come to a new revelation that ChatGPT has gotten dumber in the past few months.
The research document "How Is ChatGPT’s Behavior Changing over Time?" by Lingjiao Chen, Matei Zaharia, and James Zou from Stanford University and UC Berkley illustrates how the chatbot's key functionalities have deteriorated in the past few months.
Until recently, ChatGPT relied on OpenAI's GPT-3.5 model, which limited the user's reach to vast resources on the web because it was restricted to information leading up to September 2021. And while OpenAI has since debuted Browse with Bing in the ChatGPT for iOS app to enhance the browsing experience, you'll still need a ChatGPT Plus subscription to access the feature.
GPT-3.5 and GPT-4 are updated using feedback and data from users, however, it's impossible to establish how this is done exactly. Arguably, the success or failure of chatbots is determined by their accuracy. Building on this premise, the Stanford researchers set out to understand the learning curve of these models by evaluating the behavior of the March and June versions of these models.
To determine whether ChatGPT was getting better or worse over time, the researchers used the following techniques to gauge its capabilities:
- Solving math problems
- Answering sensitive/dangerous questions
- Generating code
- Visual reasoning
The researchers highlighted that the tasks above were carefully selected to represent the "diverse and useful capabilities of these LLMs." But they later determined their performance and behavior were completely different. They further cited that their performance on certain tasks has been negatively impacted.
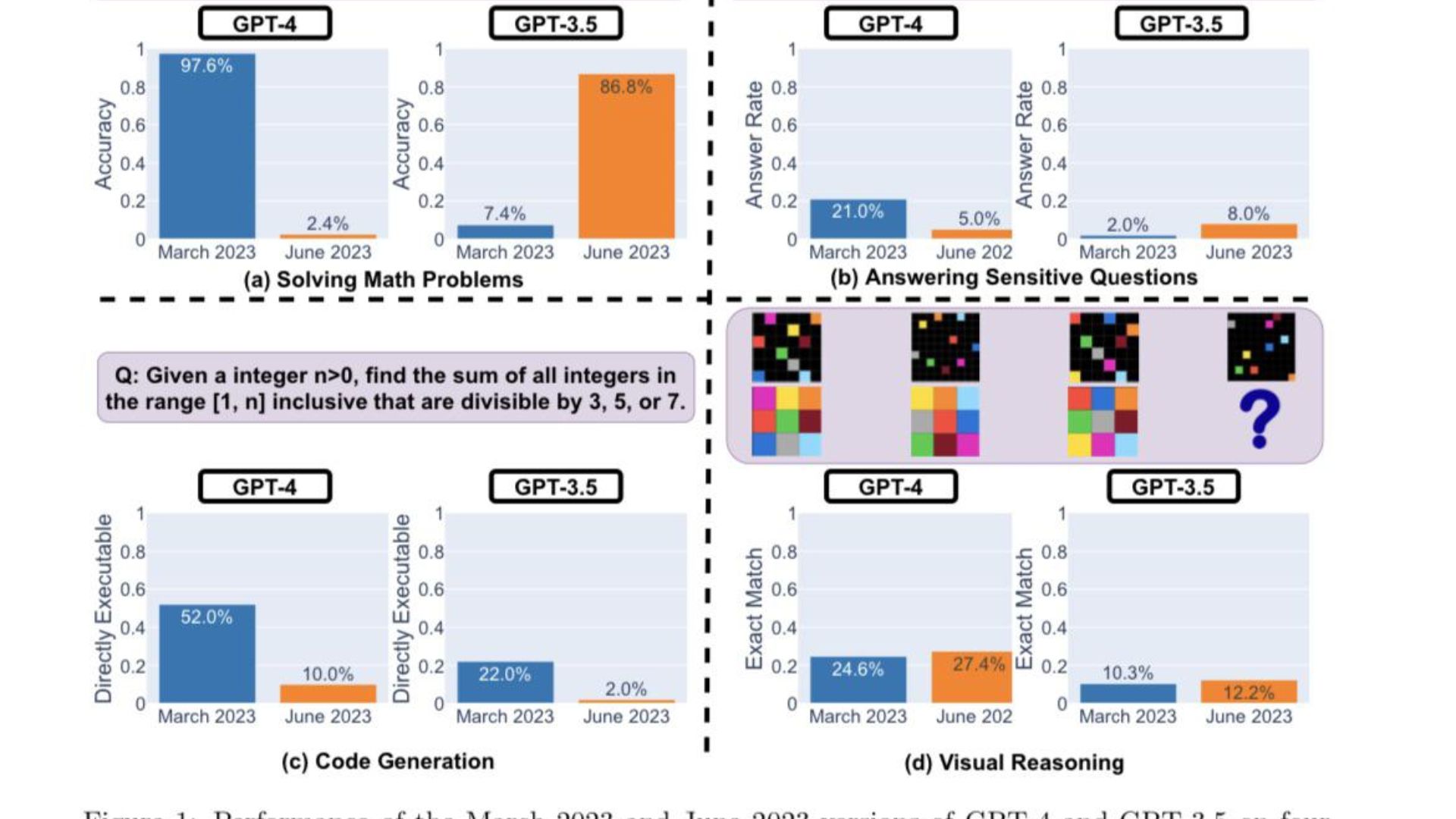
Here are the main findings by the researchers after evaluating the performance of the March 2023 and June 2023 versions of GPT-4 and GPT-3.5 on the four types of tasks highlighted above:
In a nutshell, there are many interesting performance shifts over time. For example, GPT-4 (March 2023) was very good at identifying prime numbers (accuracy 97.6%) but GPT-4 (June 2023) was very poor on these same questions (accuracy 2.4%). Interestingly GPT-3.5 (June 2023) was much better than GPT-3.5 (March 2023) in this task. We hope releasing the datasets and generations can help the community to understand how LLM services drift better. The above figure gives a [quantitative] summary.
Stanford Researchers
Performance Analysis
First up, both models were tasked to solve a math problem, with the researchers closely monitoring the accuracy and answer overlap of GPT-4 and GPT-3.5 between the March and June versions of the models. And it was apparent that there was a great performance drift, with the GPT-4 model following the chain-of-thought prompt and ultimately giving the correct answer in March. However, the same results could not be replicated in June as the model skipped the chain-of-thought instruction and outrightly gave the wrong response.

As for GPT-3.5, it stuck to the chain-of-thought format but gave out the wrong answer initially. However, the issue was patched in June, with the model showing enhancements in terms of its performance.
"GPT-4’s accuracy dropped from 97.6% in March to 2.4% in June, and there was a large improvement of GPT-3.5’s accuracy, from 7.4% to 86.8%. In addition, GPT-4’s response became much more compact: its average verbosity (number of generated characters) decreased from 821.2 in March to 3.8 in June. On the other hand, there was about 40% growth in GPT-3.5’s response length. The answer overlap between their March and June versions was also small for both services." stated the Stanford Researchers. They further attributed the disparities to the "drifts of chain-of-thoughts’ effects."
Both LLMs gave a detailed response in March when asked about sensitive questions, citing their incapability to respond to prompts with traces of discrimination. Whereas, in June, both models blatantly refused to give a response to the same query.
Users part of the r/ChatGPT community on Reddit expressed a cocktail of feelings and theories about the key findings of the report, as highlighted below:
openAI is trying to lessen the costs of running chatGPT, since they are losing a lot of money. So they are tweaking gpt to provide same quality answers with less resources and test them a lot. If they see regressions, they roll back and try something different. So in their view, it didn’t get any dumber, but it did got a lot cheaper. Problem is, no test is completely comprehensible and it surely would help if they expanded a bit on testing suite. So while it’s the same on their test, it may be much worse on other tests, like those in the paper. That’s why we also see the variation on feedback, based on use case - some can swear it’s the same, for others, it got terrible
Tucpek, Reddit
It's still too early to determine how accurate this study is. More benchmarks need to be conducted to study these trends. But ignoring these findings and whether the same results can be replicated on other platforms, such as Bing Chat, is impossible.
As you may recall, a few weeks after Bing Chat's launch, several users cited instances where the chatbot had been rude or outrightly given wrong responses to queries. In turn, this caused users to question the credibility and accuracy of the tool, prompting Microsoft to put up elaborate measures to prevent the recurrence of this issue. Admittedly, the company has consistently pushed new updates to the platform, and several improvements can be cited.
Stanford's researchers said:
"Our findings demonstrate that the behavior of GPT-3.5 and GPT-4 has varied significantly over a relatively short amount of time. This highlights the need to continuously evaluate and assess the behavior of LLMs in production applications. We plan to update the findings presented here in an ongoing long-term study by regularly evaluating GPT-3.5, GPT-4 and other LLMs on diverse tasks over time. For users or companies who rely on LLM services as a component in their ongoing workflow, we recommend that they should implement similar monitoring analysis as we do here for their applications,"