
Leading AI companies have been bragging about the number of GPUs they use or plan to use in the future. Just yesterday, OpenAI announced plans to build infrastructure to power two million GPUs, but now Elon Musk has revealed even more colossal plans: the equivalent of 50 million H100 GPUs to be deployed for AI use over the next five years. But while the number of H100 equivalents looks massive, the actual number of GPUs to be deployed may not be quite as great. Unlike the power they will consume.
50 ExaFLOPS for AI training
"The xAI goal is 50 million in units of H100 equivalent-AI compute (but much better power-efficiency) online within 5 years," Elon Musk wrote in an X post.
One Nvidia H100 GPU can deliver around 1,000 FP16/BF16 TFLOPS for AI training (these are currently the most popular formats for AI training), so 50 million of such AI accelerators will have to deliver 50 FP16/BF16 ExaFLOPS for AI training by 2030. Based on the current performance improvement trends, this is more than achievable over the next five years.
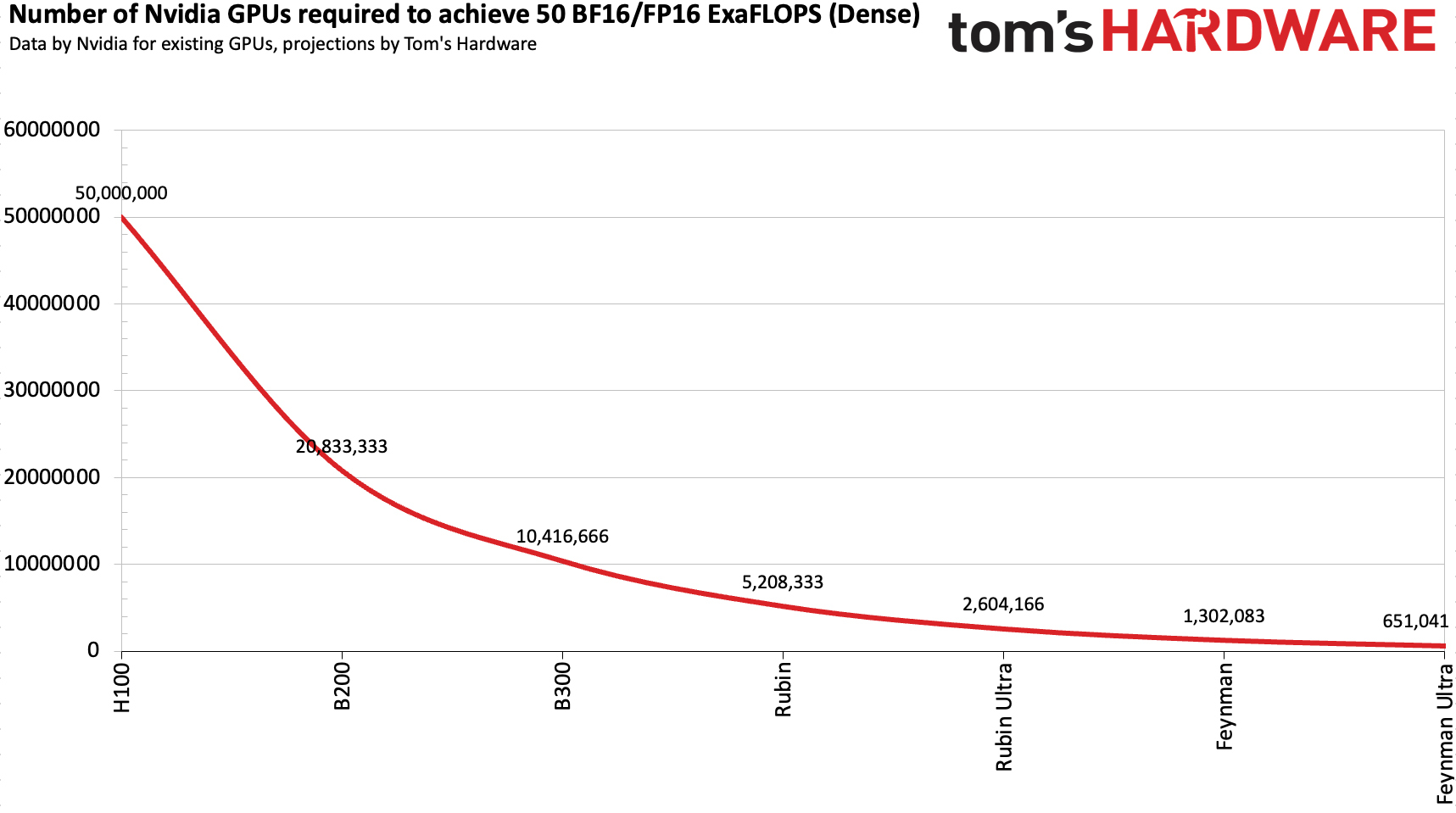
Only 650,000 Feynman Ultra GPUs
Assuming that Nvidia (and others) will continue to scale BF16/FP16 training performance of its GPUs at a pace slightly slower than with the Hopper and Blackwell generations, 50 BF16/FP16 ExaFLOPS will be achievable using 1.3 million GPUs in 2028 or 650,000 in 2029, based on our speculative guesses.
If xAI has enough money to spend on Nvidia hardware, it is even possible that the goal of getting to 50 ExaFLOPS for AI training will be achieved even earlier.
Elon Musk's xAI is already among the fastest companies to deploy the latest AI GPU accelerators to boost its training capability. The company already runs its Colossus 1 supercluster that uses 200,000 H100 and H200 accelerators based on the Hopper architecture, as well as 30,000 GB200 units based on the Blackwell architecture. In addition, the company aims to build its Colossus 2 cluster consisting of 550,000 GB200 and GB300 nodes (each of such nodes has two GPUs, so the cluster will feature over a million GPUs) with the first nodes set to come online in the coming weeks, according to Musk.
Steady performance increases
Nvidia (and other companies) recently switched to a yearly cadence of new AI accelerators release and Nvidia's schedule now resembles Intel's Tick-Tock model from back in the day though in this case we are talking about an architecture -> optimization approach using a single production node (e.g., Blackwell -> Blackwell Ultra, Rubin -> Rubin Ultra) rather than switching to a new process technology for a known architecture.
Such an approach ensures significant performance increases every year, which in turn ensures dramatic longer-term performance gains. For example, Nvidia claims its Blackwell B200 delivers 20,000 times higher inference performance than the 2016 Pascal P100, offering around 20,000 FP4 TFLOPS versus the P100’s 19 FP16 TFLOPS. Though not a direct comparison, the metric is relevant for inference tasks. Blackwell is also 42,500 times more energy efficient than Pascal when measured by joules per generated token.
Year |
2022 |
2023 |
2024 |
2025 |
2026 |
2027 |
Architecture |
Hopper |
Hopper |
Blackwell |
Blackwell Ultra |
Rubin |
Rubin |
GPU |
H100 |
H200 |
B200 |
B300 (Ultra) |
VR200 |
VR300 (Ultra) |
Process Technology |
4N |
4N |
4NP |
4NP |
N3P (3NP?) |
N3P (3NP?) |
Physical Configuration |
1 x Reticle Sized GPU |
1 x Reticle Sized GPU |
2 x Reticle Sized GPUs |
2 x Reticle Sized GPUs |
2 x Reticle Sized GPUs, 2x I/O chiplets |
4 x Reticle Sized GPUs, 2x I/O chiplets |
FP4 PFLOPs (per Package) |
- |
- |
10 |
15 |
50 |
100 |
FP8/INT6 PFLOPs (per Package) |
2 |
2 |
4.5 |
10 |
? |
? |
INT8 PFLOPS (per Package) |
2 |
2 |
4.5 |
0.319 |
? |
? |
BF16 PFLOPs (per Package) |
0.99 |
0.99 |
2.25 |
5 |
? |
? |
TF32 PFLOPs (per Package) |
0.495 |
0.495 |
1.12 |
2.5 |
? |
? |
FP32 PFLOPs (per Package) |
67 |
67 |
1.12 |
0.083 |
? |
? |
FP64/FP64 Tensor TFLOPs (per Package) |
34/67 |
34/67 |
40 |
1.39 |
? |
? |
Memory |
80 GB HBM3 |
141 GB HBM3E |
192 GB HBM3E |
288 GB HBM3E |
288 GB HBM4 |
1 TB HBM4E |
Memory Bandwidth |
3.35 TB/s |
4.8 TB/s |
8 TB/s |
4 TB/s |
13 TB/s |
32 TB/s |
GPU TDP |
700 W |
700 W |
1200 W |
1400 W |
1800 W |
3600 W |
CPU |
72-core Grace |
72-core Grace |
72-core Grace |
72-core Grace |
88-core Vera |
88-core Vera |
Indeed, Nvidia and others are not slowing down with performance advancements. The Blackwell Ultra architecture (B300-series) offers a 50% higher FP4 performance (15 FPLOPS) compared to the original Blackwell GPUs (10 FPLOPS) for AI inference, as well as two times higher performance for BF16 and TF32 formats for AI training, yet at the cost of lower INT8, FP32, and FP64 performance. For reference, BF16 and FP16 are typical formats used for AI training (though FP8 seems to be evaluated as well), so it is reasonable to expect Nvidia to boost performance in these formats with its next-generation Rubin, Rubin Ultra, Feynman, and Feynman Ultra GPUs.
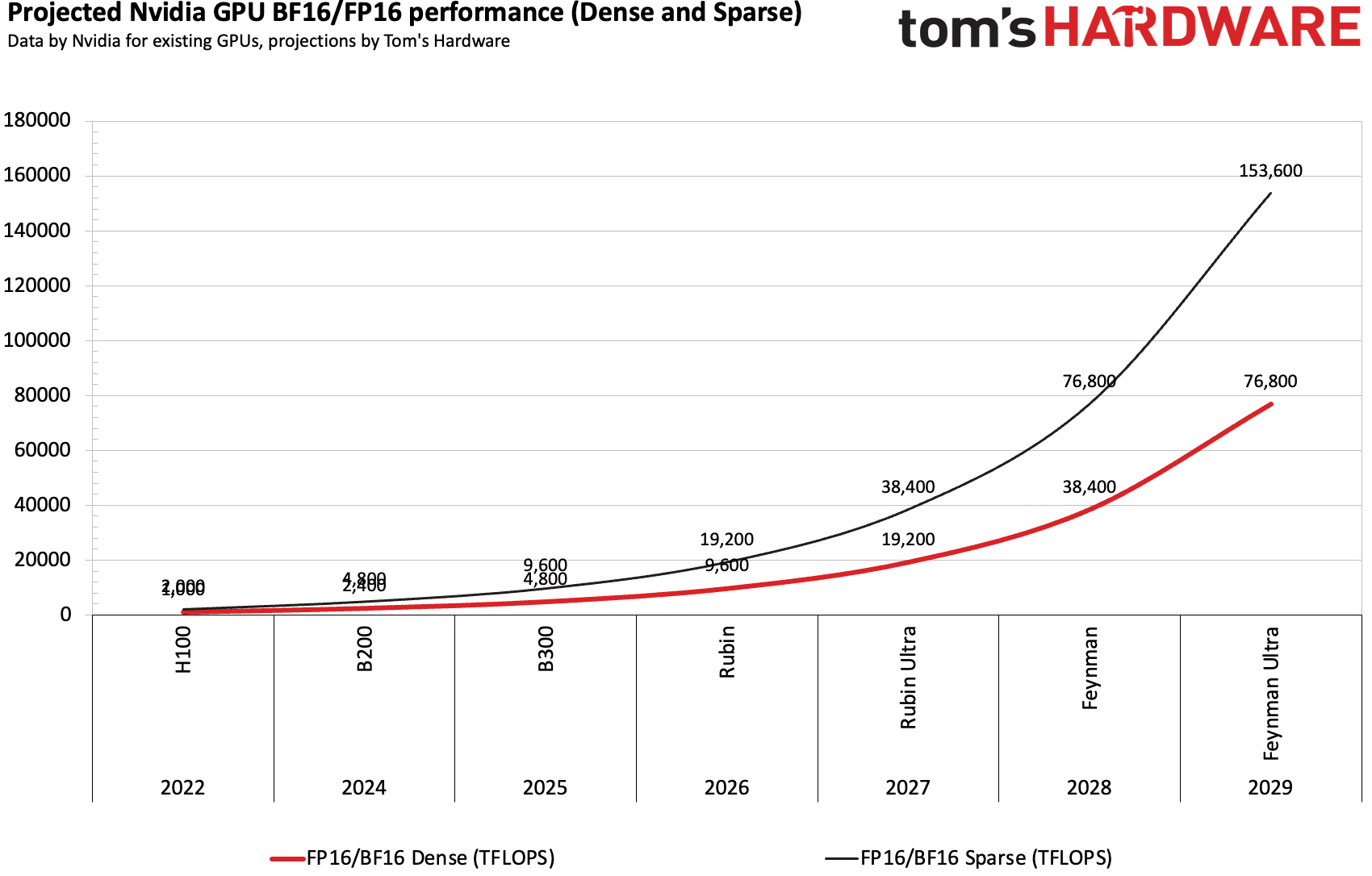
Depending on how we count, Nvidia increased FP16/BF16 performance by 3.2 times with H100 (compared to A100), then by 2.4 times with B200 (compared to H100), and then by 2.2 times with B300 (compared to B200). Actual training performance of course depends not only on pure math performance of new GPUs, but also on memory bandwidth, model size, parallelism (software optimizations and interconnect performance), and usage of FP32 for accumulations. Yet, it is safe to say that Nvidia can double the training performance (with FP16/BF16 formats) of its GPUs with each new generation.
Assuming that Nvidia can achieve the aforementioned performance increases with its four subsequent generations of AI accelerators based on the Rubin and Feynman architectures, it is easy to count that around 650,000 Feynman Ultra GPUs will be needed to get to around 50 BF16/FP16 ExaFLOPS sometime in 2029.
Gargantuan power consumption
But while Elon Musk's xAI and probably other AI leaders will probably get their 50 BF16/FP16 ExaFLOPS for AI training over the next four or five years, the big question is how much power will such a supercluster consume? And, how many nuclear power plants will be needed to feed one?
One H100 AI accelerator consumes 700W, so 50 million of these processors will consume 35 gigawatts (GW), which is equal to the typical power generated by 35 nuclear power plants, making it unrealistic to power such a massive data center today. Even a cluster of Rubin Ultra will require around 9.37 GW, which is comparable to the power consumption of French Guiana. Assuming that the Feynman architecture doubles performance per watt for BF16/FP16 compared to the Rubin architecture (keep in mind that we are speculating), a 50 ExaFLOPS cluster will still need 4.685 GW, which is well beyond 1.4 GW – 1.96 GW required for xAI's Colossus 2 data center with around a million AI accelerators.
GPU Model |
TFLOPS (Dense) |
Power per GPU (W) |
GPUs Needed |
Total Power (GW) |
H100 |
1,000 |
700 |
50,000,000 |
35 |
B200 |
2,400 |
1,200 |
20,833,333 |
25.00 |
B300 |
4,800 |
1,400 |
10,416,666 |
14.58 |
Rubin |
9,600 |
1,800 |
5,208,333 |
9.37 |
Rubin Ultra |
19,200 |
3,600 |
2,604,166 |
9.37 |
Feynman |
38,400 |
? |
1,302,083 |
4.685 (?) |
Can Elon Musk's xAI get 4.685 GW of power to feed a 50 ExaFLOPS data center in 2028 – 2030? That is something that clearly remains to be seen.
Follow Tom's Hardware on Google News to get our up-to-date news, analysis, and reviews in your feeds. Make sure to click the Follow button.







