Artificial intelligence models will follow you even if you told it (him?) to jump off a bridge, figuratively.
The point that I'm trying to get across is that they'll listen to you unconditionally, any written instruction will be "end-all, be-all" for it (apart from few no-go areas), sometimes it gets things too literal. Despite that, most teams still wonder why their chatbots hallucinate facts, bury the lead, or spit out unusable text.
Granted, lately this has been dependent on the model version you're using (with ChatGPT, at least), because some of them are missing the mark by a (token) mile, which is why we internally stick with the o3 model. Although, I can already feel how this will not age well due to the fact how things are moving so fast in this industry.
I've watched dozens of prompts being copied and pasted with the stock “Act as an expert” opener, followed up with the keyboard's hollow sounding return key hitting the bottom of the switch, and a sigh released in hopes that you'll see a little bit of that AI computing magic.
When it flops, the model is the one that takes the blame.
At Direcut, we first start by trying, observing, reiterating, and then fixing the prompt, because the words you write before you hit that "Send" - are the only levers you fully control.
Why Well-Meaning Prompts Fail
The extra "pleases" and "thank yous" won't help get the job done. Large language models are sensitive to context, order, and hidden assumptions (they can't read minds - YET). If you leave the door wide open, they'll walk right in with a huge bucket of what they think you thought you'd like to see it spit out, while you were typing that prompt. 9/10 times their answer ends up being way too broad, leaving it in the hands of the LLM to "do its best."
Knowing that prompt engineering isn’t something new, and that it's here to stay (very likely to replace regular search engines), the sooner you adapt, the better. Not only for you as an end user, but for companies as well. Some of them already have, making it a part of a large business model for a lot of core services Candy AI has built, for example. They have a whole powerhouse depended on using LLM’s and mastering their in-house prompt engineering. It's all about getting the message across, but the key lies in how.
A prompt that feels clear to its author can be ambiguous to the model because it's:
- Missing his role definition. The model lacks a point of view, so its tone swings between press release and teen slang. You need to guide its persona.
- Receiving implicit data without context. The prompt often assumes shared knowledge about brand guidelines or product specs that the model has never seen.
- Working with competing and redundant instructions. I often see people asking the model to summarize something quickly, while also expanding on every pain point, producing contradictions.
- Getting ambiguous metrics without substance. We ask for engaging copy but never define engagement.
- Oversizing context windows. Some users paste a twelve-page white paper, then ask for a tweet, so the model spends most of its token budget parsing irrelevant information.
You can think of it like this - if your "temperature setting" is too high, the model will start hallucinating statistics it thinks will sound impressive (funnily enough, there's a such setting in ChatGPT's Playground).
That's not just me pulling things out of nowhere, according to the June 2025 OpenAI technical note hallucinations can and will occur when prompts omit grounding references, and users started to report it more frequently.
Before it was garbage in, garbage out, now it's fuzzy inputs, fuzzy outputs.
Direcut’s Four-Step Fixer Upper Process
We treat every broken prompt like a mini engineering bug, which is why we do the following:
- Implement constraints. Brand style guides, target word counts, and must-keep facts (and user's and model's self-fact checking) become explicit bullet points. Up-front constraints will "free" the model to be creative inside a sandbox you've created.
- Define role and output schema. The model’s persona and format expectations are stated up front, more advanced users use JSON keys, while at Direcut we use Markdown headings. This secures us from getting that wishy-washy voice.
- Sequence tasks in a logical order. Complex asks become numbered steps, helping the model to reason through them.
- Test, measure, iterate. Repeat. Each revision runs through our checking procedure, and we tweak until variance drops below five percent.
That last step is extremely important. Our internal benchmark shows a 45% reduction in post-edit time when prompts are iterated at least twice before using the information or content we were asking for, and that was based on 120 client articles logged in the first two quarters of 2025.
Why We Prefer the OpenAI Playground
We ran these test prompts inside the OpenAI Playground, as with all our work, and not the public chat interface. This enables us to do the following:
- Lock a specific model version for reproducibility or compare them
- Store tested prompts
- Adjust temperature, top-p, and system instructions
- Gives us a hackerman-feel because of how the interface looks (proven benefits still pending)
Using the Playground also means the demo prompts that follow below can be reproduced exactly, so you can paste the"Updated"versions directly into the Playground, choose modelgpt-4.1, and compare your results with ours.
Every example in this article was validated in that environment.
The Metrics We Track
- Post-edit distance (PED). Levenshtein characters changed divided by total characters.
Our goal: below 0.15. - Hallucination incidents per 1 000 tokens.
Our goal: below 0.3. - Turnaround time. From initial prompt to client-ready draft.
Our goal: forty-eight hours for long-form pieces, one hour for social posts.
Before-and-After Prompt Fixes You Can Try
Below are three real scenarios we used last quarter (details adjusted for privacy). Again, you can open a new Playground session, paste the updated version, watch the difference and follow along.
Link-Building Article Campaign Ideation
Original Version
Prompt: "Suggest me 20 different topics about AI tech for our writers to explore and dig deeper."
Why is this a bad prompt?
- No industry or audience defined
- No style or tone direction
- No specifications were not supplied
Updated Prompt
Role: You are a senior copywriter for Direcut’s client.
Audience: Tech-savvy millennials who are interested in AI trends and applications.
Task sequence (respond in this order):
- Generate 20 unique AI tech topics specifically about the AI industry
- Each topic idea should be maximum 10 words
- Include a one-sentence description explaining the angle or focus of the article.
- Additional Requirements:
Cover a mix of subtopics, such as AI ethics, generative models, real-world business use cases, cultural impacts, and emerging research
Avoid duplicate angles or repetitive phrasing
Style: Informed and engaging, clear language without excessive jargon, appropriate for a professional but curious audience
Paste that into the Playground, the bullet will stay short, it will match the audience wants and attention hooks, and topic suggestions are not all over the place.
Social Media Reels Script Outline
Original Version
Prompt: "Outline a two-minute video for our channel."
Why is this a bad prompt?
- Two minutes can be interpreted in many pacing styles
- No specific topic
- Channel’s quirky voice not specified
- No call-outs for B-roll or graphics
Updated Prompt
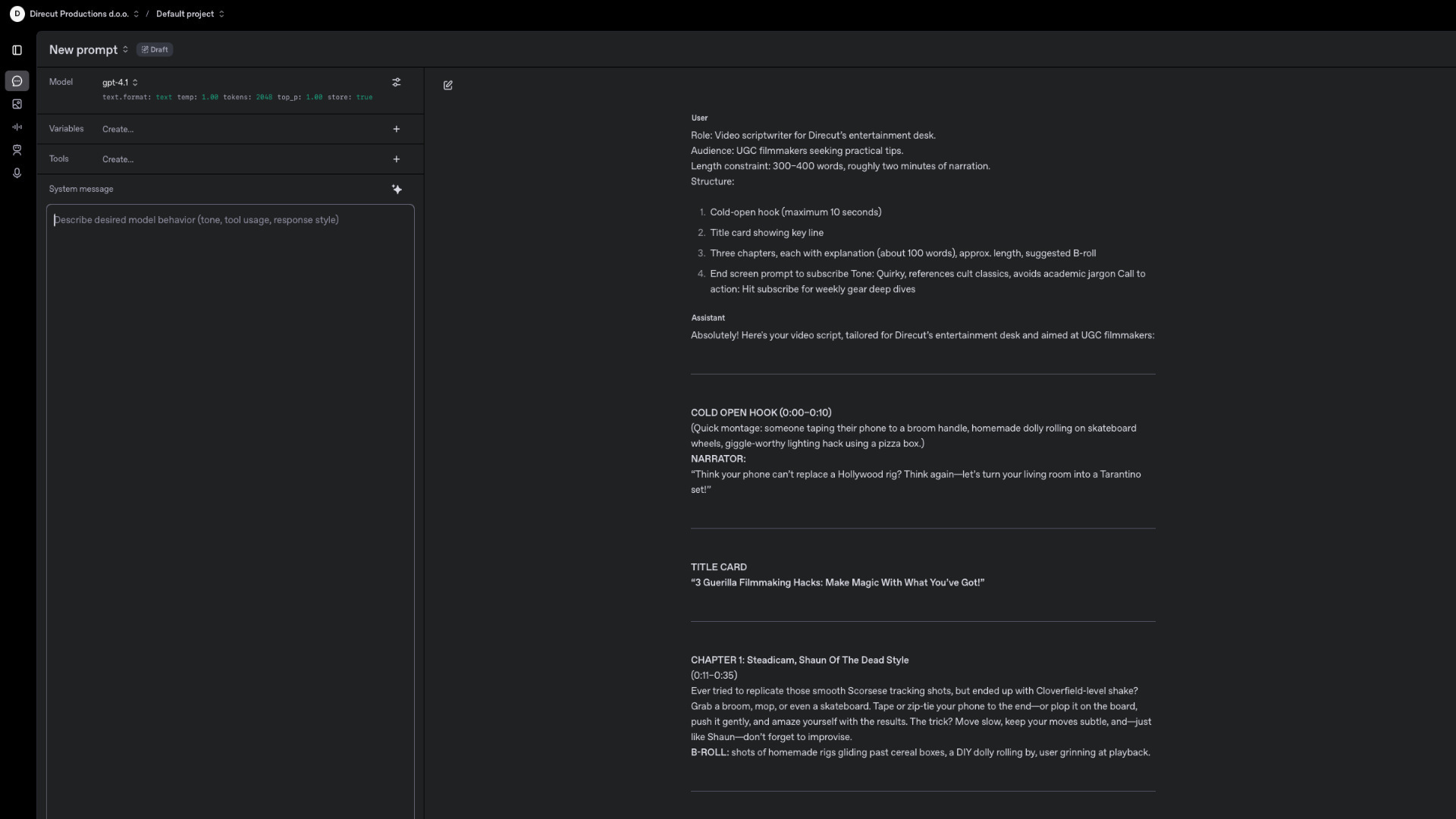
Role: Video scriptwriter for Direcut’s entertainment desk.
Audience: UGC filmmakers seeking practical tips.
Length constraint: 300–400 words, roughly two minutes of narration.
Structure:
- Cold-open hook (maximum 10 seconds)
- Title card showing key line
- Three chapters, each with explanation (about 100 words), approx. length, suggested B-roll
- End screen prompt to subscribe
Tone: Quirky, references cult classics, avoids academic jargon
Call to action: Hit subscribe for weekly gear deep dives
Run it in the Playground and you will get a neatly labeled outline with time stamps and B-roll suggestions, ready for your editor.
Investor Update Slide Copy
Original Version
Prompt: "Write an information outline for a slide about our Q2 numbers."
Why is this a bad prompt?
- No actual numbers provided
- Unclear narrative angle
- Slide-deck style not defined
Updated Prompt
Role: Investor-relations writer at Direcut working for a client in automotive industry.
Data provided:
- Revenue 12.4 million euros (up 18 percent quarter over quarter)
- Net retention rate 132 percent
- Cash runway 28 months
Task: Draft headline, three bullet insights, and one takeaway sentence emphasizing sustainable growth.
Tone: Analytical, avoids buzzwords.
Length constraint: 60–70 words.
Output format: Markdown list.
By feeding the real numbers and a narrative brief, the model stops guessing and produces investor-safe language.
Case Study: From Eight Hours to Forty-Five Minutes
Last March, an AI tech client came to us with a 2,000-word prompt that told the model to draft a product overview memo, generate three slide decks, and brainstorm social captions in one go. Editors spent eight billable hours untangling the result, while we simultaneously isolated each deliverable, created three focused prompts, and attached the relevant data tables.
The next run hit 0.08 PED accuracy and needed only minor line edits, cutting the cycle to forty-five minutes.
Measurable Impact
- Editor hours saved: seven-hour reduction per memo
- Stakeholder satisfaction: 8.7 out of 10 survey score, up from 6.7
- Compliance flags: one, while the original draft triggered four policy alerts
One of the project holders told us -"This alone covered your retainer for the quarter."
Common Anti-Patterns to Avoid
- Never-ending laundry-list prompts. Bullets separated only by commas confuse token boundaries; convert them into numbered tasks.
- Tone sandwich without sauce. Opening line says formal, middle says fun, and end says quirky. Pick just one.
- Shotgun temperature rise. Switching from 0.1 to 2.0 mid-session will cause a style drift.
- Unanchored continuations. Using"Continue"without context relies on model memory, which can be unreliable more often than not, so try to avoid it, even delete thread/prompts and start all over again.
Eventually you'll start spotting these patterns, and you'll come to the conclusion that it's better to rewrite them than tweak settings. In our experience, a clear prompt beats a clever one every time.
Quick Reference Checklist
Before you hit "Send" on your next LLM request, here's a quick sanity-check list:
- Be explicit about the role and audience
- Quantify length targets
- Paste or link reference data
- Tone keywords need to be singular
- Use JSON or Markdown output format
Write this down on a yellow sticky note and paste it above your monitor. It'll save you from any future headaches.
Getting Started with Direcut
If you visit our website, you'll notice that prompt engineering is not our core business, but it's a tool that we use daily, and we're 100% sure it will seep into every other industry, they're just still figuring it out.
Although we won't offer you a prompt audit, we do tie it in with our full-service content production. We're always open for jumping on a 30-minute discovery call, you'll receive a bespoke offer based on your needs, while we'll also toss in a piece of advice or two about prompting - pro bono!
Request a Prompt Rescue
Send us your worst-performing prompt withPrompt SOSin the subject line and we will reply within one business day with a free mini fix, plus options for deeper collaboration. Who knows, maybe we do end up listing this as a service.