
The world of AI is competitive. Theoretically, most of the major AI models you’ve heard of are on a similar level. They all offer fairly similar packages and features with few notable differences on the surface.
However, when you dig a little deeper, they all exist on a scale. AI models are constantly tested and benchmarked. These can be tests of their emotional intelligence, coding ability, writing skills, or even just their ability to process tests of logic.
This is where, in a world of small margins, these models have the opportunity to come out on top. For the last couple of months, Google’s Gemini dominated most of these tests, then xAI’s Grok stepped in with an update to match Gemini.
Now, GPT-5 is here. For months, Altman and his team have hyped this up as an industry-defining update. So, now that it has arrived, is this actually true?

At first, OpenAI showed off its own benchmarking. It showed what everyone expected: a major upgrade in every single area. Except, as The Verge reported, the graphs weren’t exactly accurate.
Yes, the numbers were right, but the bar graphs used made OpenAI look like it was miles ahead. Looking closer at the numbers, it was closer to having a slight lead.
Now, available to the public, GPT-5 has been put through external benchmarks separate from OpenAI. This is how it really scored.
How GPT-5 scored on benchmark tests
Vellum
These tests can range in their evaluations. They can involve asking AI models multiple choice questions, making them solve puzzles, or simply analysing the configurations behind the scenes.
Vellum, an AI benchmarking company, tests models across a wide range of areas. In the company’s LLM leaderboard, GPT-5 takes the top spot for both reasoning (its understanding of biology, physics, and chemistry), with Grok 4 scoring just 2% below it and Gemini 3% behind it.
GPT-5 also leads the table on high school math ability, with two other OpenAI models following behind it. It came second behind Grok 4 in coding ability (but only by 0.1%).
However, it was nowhere to be seen in tests of adaptive reasoning (how well a model adapts to new concepts instead of relying on pre-learned patterns) — a skill which Gemini and Anthropic’s Claude led on.
Artificial Analysis
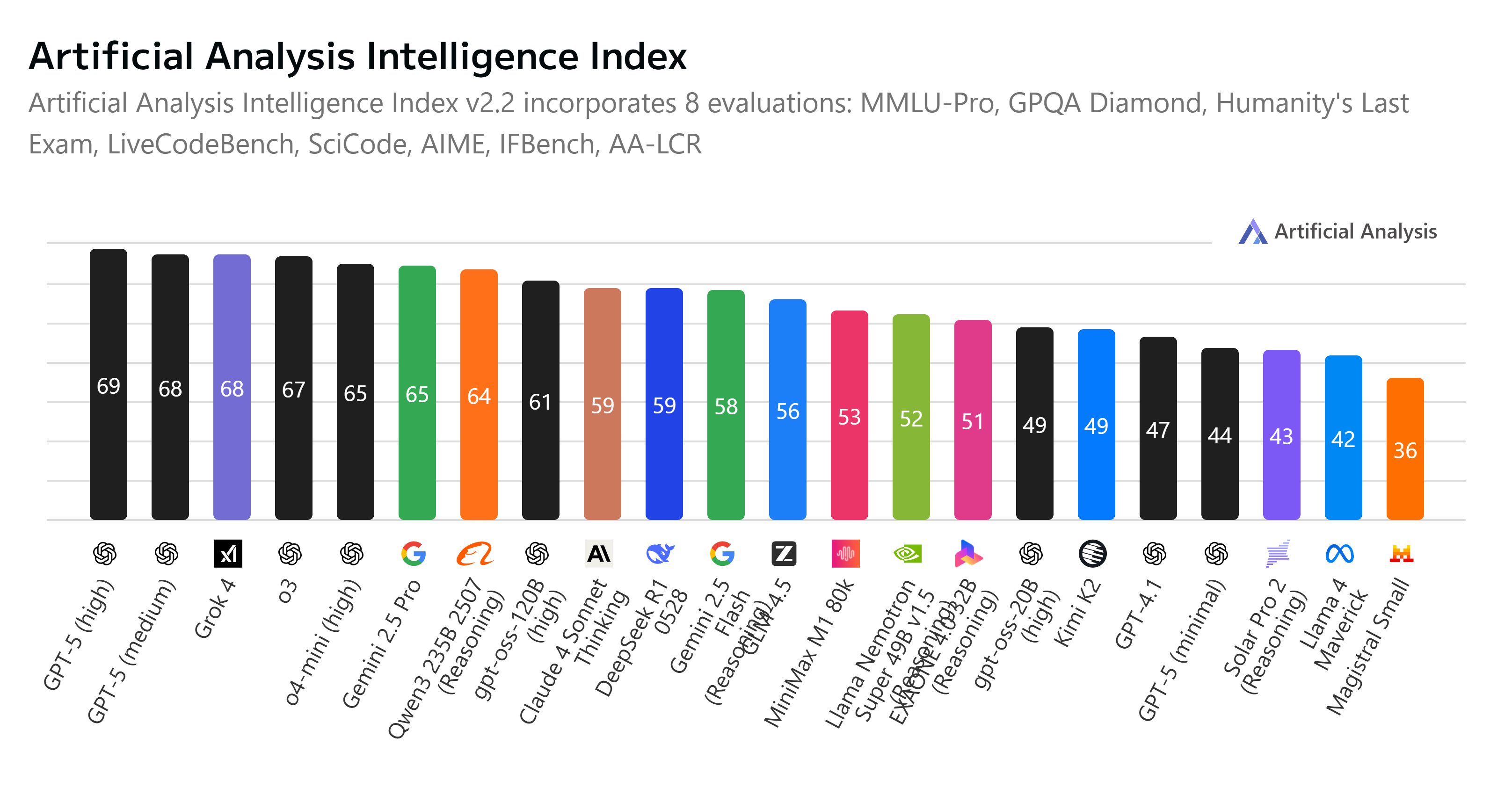
Another popular AI benchmarking leaderboard comes from Artificial Analysis. The ranking board tests models on key metrics including intelligence, price, performance, and speed.
In this testing method, GPT-5 takes the top two spots, with its high effort and medium effort models. GPT-5 just scrapes past Grok 4 in the benchmark for model intelligence, scoring 69 (Grok 4 scored 68).
LMArena
LMArena tests models across a wide range of categories. These focus on the model’s generation ability with text, code, images, video, and more.
The ranking comes from a combination of votes from the public and in-house testing. GPT-5 came 1st for text, coding, and its ability to understand and process visual inputs.
GPT-5 was also the number one AI model in the company’s arena. This is where hundreds of AI models compete on coding, maths, creative writing, instruction following, and more.
GPT-5 led in all of these categories in the company’s tests, beating out Anthropic Claude and Gemini in the following positions.
LiveBench

This is one of the better-known tests for AI. LiveBench includes a set of 21 diverse tasks across 7 categories. Each question asked has verifiable objective answers. This removes risks of variability with clear answers needed.
GPT-5 currently takes the top three spots in the leaderboard through its high, medium, and low versions. GPT-5 high had the highest score on reasoning, coding and agentic coding. It also led with a significant lead in mathematics and language.
SimpleBench
In the lead-up to GPT-5’s launch, there were rumours that the update would be the first AI model to beat the human baseline on SimpleBench.
This is a multiple-choice text benchmark for AI. Individuals with high school-level knowledge were asked over 200 questions covering spatio-temporal reasoning, social intelligence, and trick questions.
No AI model has managed to beat the human average on this test. So what about GPT-5? Not only did it not beat the human average of 83.7%, but it actually came 5th, falling behind Gemini 2.5 Pro, Grok 4, and two Claude 4 models.
Does GPT-5 live up to the hype?
We are still early in the life of GPT-5. According to these early tests, OpenAI’s latest update is leading the charge in the vast majority of areas. However, it is worth noting that, while it is at the top of the leaderboards, it is only by a small margin.
In most areas, GPT-5 leads by a small percentage, and in some cases, it is winning when all factors are looked at. That doesn’t necessarily mean it is the best option in all situations but the best overall.
There are also plenty of other benchmark tests that the model needs to be tested on. Over the next few months, we’ll see how GPT-5 stacks up against the competition across a wide variety of skills and tests.
However, for now, GPT-5 does seem to have the lead, especially in areas where GPT-5 saw the biggest updates. That includes creative writing, coding, and health-based questions.







