
AI models like OpenAI’s ChatGPT and Google’s Gemini have run out of training data, according to Goldman Sachs’ data chief.
Neema Raphael, who serves as the banking giant’s chief data officer and head of data engineering, said the issue could stunt the development of artificial intelligence.
“We’ve already run out of data,” Mr Raphael said on the bank’s Exchanges podcast, adding that AI models are increasingly turning to so-called synthetic data generated by artificial intelligence.
"I think what might be interesting is people might think there might be a creative plateau... If all of the data is synthetically generated, then how much human data could then be incorporated? I think that'll be an interesting thing to watch from a philosophical perspective.”
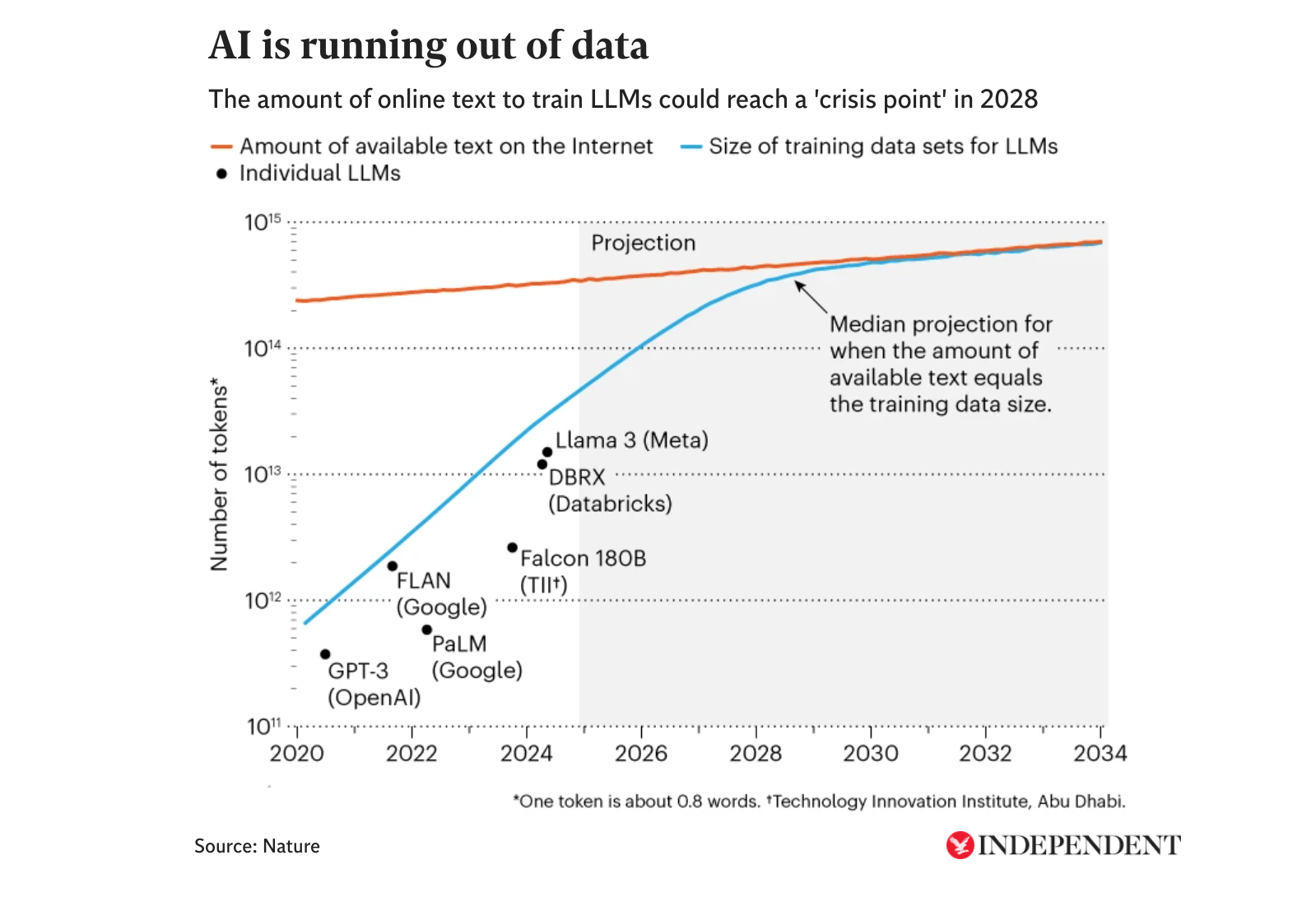
It is not the first time that senior industry figures have raised concerns about the issue, referred to as “peak data”, whereby AI models consume all of the internet’s vast troves of information.
An article in the journal Nature in December predicted that a “crisis point” would be reached by 2028. “The internet is a vast ocean of human knowledge, but it isn’t infinite,” the article stated. “Artificial intelligence researchers have nearly sucked it dry.”
OpenAI co-founder Ilya Sutskever said last year that the lack of training data would mean that AI’s rapid development “will unquestionably end”.
The situation is similar to fossil fuels, according to Mr Sutskever, as human-generated content is a finite resource just like oil or coal.
“We’ve achieved peak data and there’ll be no more,” he said. “We have to deal with the data that we have. There’s only one internet.”
The lack of new data could force AI companies to shift away from current training models, switching focus from large language models like ChatGPT towards more agentic artificial intelligence.
AI agents, which are already being developed and released by most major artificial intelligence firms, serve as autonomous systems that can make decisions and perform tasks online without human oversight.







