
A small research group recently examined the performance of 25 AI 'people', using two large language models created by OpenAI, in an online Turing test. None of the AI bots ultimately passed the test, but all the GPT 3.5 ones were so bad that a chatbot from the mid-1960s was nearly twice as successful as passing off as a human. Mostly because real people didn't believe it was really AI.
News of the work was reported by Ars Technica and it's a fascinating story. The Turing test itself was first devised by famed mathematician and computer scientist Alan Turing, in the 1950s. The original version of the test involves having a real person, called an evaluator, talk to two other participants via a text-based discussion. The evaluator knows that one of the respondents is a computer but doesn't know which one.
If the evaluator can't tell which one is a computer or determines that they must both be humans, then the machine can be said to have passed the Turing test.
Cameron Jones and Benjamin Bergen of the University of California San Diego devised a two-player version of the Turing test, where an 'interrogator' asks questions of a 'witness' and then decides whether the witness is a human being or an AI chatbot. A total of 25 large language model (LLM) witnesses were created, based on the GPT-4 and GPT-3.5 models from OpenAI.
To get some baseline results, real people were also included, as was one of the first-ever chatbots created, ELIZA in the mid-1960s (you can try it out yourself here). The AI witnesses were prompted as to the nature of the discussion, along with instructions on how it should respond. These included things like making spelling mistakes, how long it should take to respond, and whether it was a human or an AI pretending to be a real person.
Just over 650 people took part in the test, with around 1,400 runs being collated to produce the analysis. Each witness was judged on how successful it was in passing off as a human being; in other words, the interrogator's final decision was that the witness was a real person.
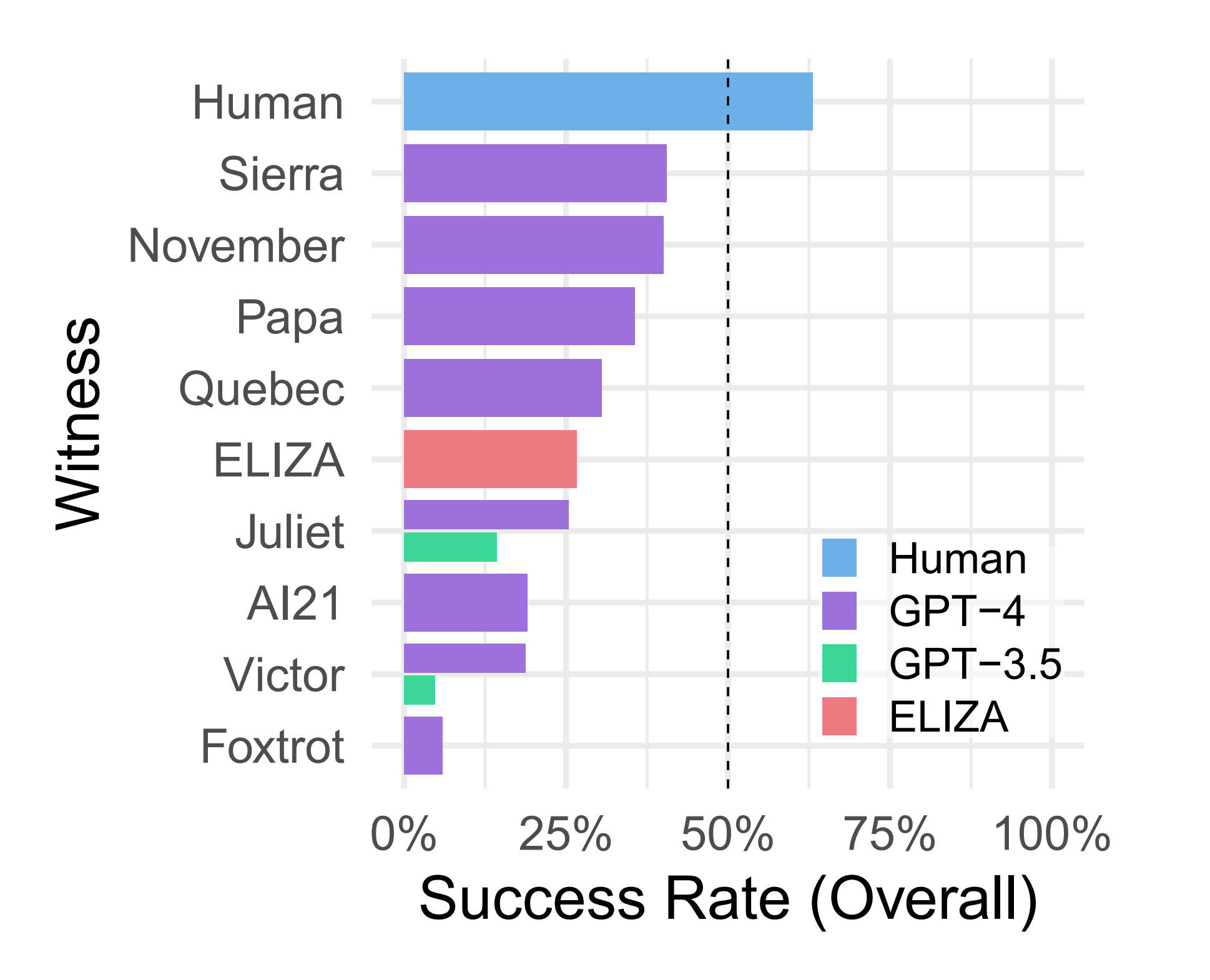
Humans had an overall success rate of 63%, which means that in 43% of the tests, interrogators thought that the real person giving the responses was an AI chatbot! The best-performing LLM witness, which used GPT-4, had an overall success rate of 43%, with the worst being just 5% (a GPT-3.5 model). That meant none of the AI bots ultimately passed the Turing test and even fared worse than just accounting for blind chance (i.e. 50%).
One big surprise was ELIZA. Created at the Massachusetts Institute of Technology, it was based on pattern checking and strict rules to give the impression that the computer genuinely understood what was being asked of it. In the study by Jones and Bergen, ELIZA achieved an overall success rate of 27%, almost double that of the best GPT-3.5 witnesses (14%).
Why did it do so much better? Part of the reason is that GPT-3.5 isn't designed to come across as a real person. The likes of ChatGPT, which uses that particular LLM, are programmed to give responses in a very fixed manner, rather than offer an opinion and then debate it.

Best gaming PC: The top pre-built machines.
Best gaming laptop: Great devices for mobile gaming.
But the main factor behind ELIZA's 'success' is that its responses are nothing like those from a modern LLM, leading to some interrogators believing it was simply too bad for it to be a real AI bot, thus assuming it had to be a person.
Given that people only managed to come across as real humans with a success rate of 63%, it's perhaps a little unfair to be overly critical of the human-ness of an LLM. Especially since the Turing test is less an examination of being human-like but more a test of how well something can deceive a person.
We're still very much in the early stages of development of large language models and who knows what it will be like in, say, ten or even just five years. Perhaps by then, games will be implementing them to flesh out NPCs in open-world games or give storylines more complexity and offer multiple paths or choices.
I don't know whether that's a bit of a scary thing to ponder over your morning coffee or not, but it certainly would make things a lot more interesting.






